Understanding Inference-Time Scaling in Large Language Models
Inference-time scaling reallocates computational resources during model generation to enhance reasoning capabilities without requiring weight updates. This approach enables systems to adjust their depth or breadth dynamically based on task complexity, offering a pragmatic alternative to continuous retraining. Understanding these mechanisms is essential for engineering teams navigating the intersection of performance optimization and infrastructure economics.
The rapid evolution of large language models has shifted architectural priorities from pretraining exclusively to post-training optimization. As organizations deploy increasingly complex reasoning systems, the boundary between training efficiency and runtime performance grows increasingly porous. Researchers now recognize that static model weights alone cannot guarantee robust performance across dynamic workloads. Instead, the focus has turned toward dynamic resource allocation during the generation phase, fundamentally altering how computational budgets are distributed across inference pipelines.
What Is Inference-Time Scaling and How Does It Differ from Training?
Training and inference represent distinct computational phases with fundamentally different optimization objectives. Pretraining involves massive gradient updates across static datasets to establish foundational pattern recognition and language representation. Inference-time scaling operates exclusively during the generation phase, where the model processes queries and produces outputs. Rather than modifying the underlying parameter matrix, this methodology adjusts how much compute the model consumes for each specific query. The distinction lies in flexibility versus permanence. Training establishes capability, while inference-time scaling governs the expression of that capability under varying constraints.
Historically, compute allocation followed a rigid paradigm where every query received identical processing depth. The modern shift recognizes that complex logical puzzles, mathematical derivations, and multi-step planning require substantially more processing cycles than straightforward factual retrieval. This realization has prompted a reevaluation of how computational budgets are distributed across runtime environments. Engineers now design systems that dynamically allocate attention heads, expand search trees, or chain multiple reasoning steps based on real-time difficulty assessment. The result is a more efficient alignment between computational expenditure and output quality.
The transition from static to dynamic compute allocation reflects a broader industry acknowledgment that model capacity is not a fixed asset. Early scaling laws emphasized parameter count and dataset size as primary drivers of capability. Contemporary frameworks recognize that runtime adaptability often yields higher marginal returns than additional pretraining cycles. This paradigm shift encourages developers to treat computational expenditure as a controllable variable rather than a permanent architectural constraint.
Why Does Test-Time Compute Matter for Reasoning Tasks?
Reasoning tasks present unique challenges that static model configurations struggle to address efficiently. Simple pattern matching benefits greatly from extensive pretraining, but multi-step logical deduction requires iterative verification and self-correction mechanisms. When a model encounters an ambiguous prompt or a mathematically dense problem, expanding its computational footprint allows it to explore multiple solution paths before committing to a final answer. This dynamic expansion prevents premature convergence on incorrect reasoning chains. The importance of test-time compute becomes evident when analyzing error distributions in complex domains.
Models that rely solely on fixed weights often exhibit confidence calibration issues, presenting plausible but flawed conclusions with high certainty. By allowing the system to allocate additional resources during challenging segments, the architecture can perform internal consistency checks and refine intermediate representations. This process mirrors human cognitive strategies where difficult problems trigger deeper analytical engagement. The practical outcome is a measurable reduction in logical fallacies and improved accuracy on benchmark datasets requiring extended deliberation. Organizations deploying these systems observe that runtime flexibility directly correlates with user trust and downstream task success.
Verification mechanisms play a critical role in this dynamic process. Rather than accepting the first generated token sequence, scalable inference architectures can trigger secondary evaluation loops that cross-reference intermediate outputs against established logical rules. This iterative refinement reduces hallucination rates and improves mathematical precision. The ability to pause and reassess during generation transforms the model from a passive text predictor into an active problem solver.
How Do Researchers Categorize Scaling Strategies?
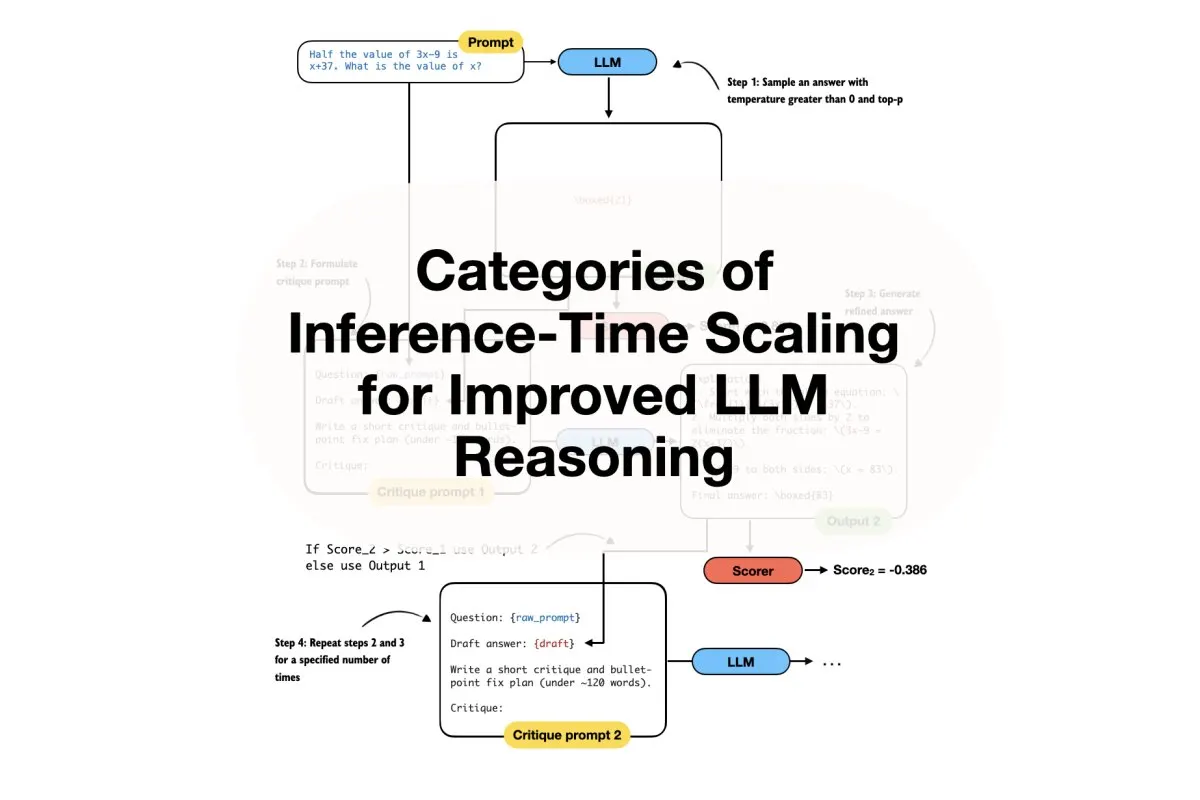
The academic and engineering communities have developed several frameworks to classify how compute expands during generation. The primary distinction separates methods that increase model depth from those that broaden parallel processing pathways. Depth scaling involves activating additional transformer layers or extending sequential reasoning steps. Each added layer refines the internal representation, allowing the model to perform more hierarchical transformations of the input context. Width scaling, conversely, maintains architectural depth while increasing the breadth of parallel search operations. This approach typically manifests through beam search expansions, diverse sampling strategies, or parallel verification modules that evaluate multiple candidate outputs simultaneously.
Some frameworks also incorporate adaptive routing mechanisms that dynamically determine whether to apply depth or width expansion based on real-time difficulty metrics. These categorizations are not mutually exclusive. Advanced implementations frequently combine both approaches, creating hybrid scaling protocols that adjust their operational mode throughout the generation process. The classification system helps researchers benchmark progress and communicate trade-offs clearly. It also provides a structured vocabulary for discussing architectural decisions during system design reviews. Understanding these categories enables engineering teams to select the most appropriate scaling methodology for their specific deployment constraints and performance requirements.
Search algorithm design further influences how scaling strategies are implemented. Tree-based exploration methods allow models to branch out during complex reasoning, evaluating multiple potential conclusions in parallel. Graph-based routing structures optimize the flow of information across different computational nodes. These algorithmic choices determine how efficiently the system navigates the solution space without exhausting available compute resources.
What Are the Architectural and Economic Trade-offs?
Implementing dynamic compute allocation introduces significant engineering complexities that extend beyond algorithmic design. The primary challenge involves latency management. Expanding computational depth inherently increases response times, which conflicts with user expectations for immediate feedback. Engineering teams must balance accuracy gains against acceptable latency thresholds, often implementing tiered scaling policies that reserve heavy computation for high-value queries. Economic considerations further complicate deployment decisions. Runtime compute costs scale linearly with the number of allocated operations, meaning aggressive scaling strategies can rapidly inflate operational expenditures. Cloud infrastructure pricing models and hardware utilization efficiency dictate the financial viability of these approaches.
Organizations frequently integrate cost-aware routing layers that evaluate query complexity before committing to expensive scaling operations. This economic layer functions as a gatekeeper, ensuring that computational resources are directed toward tasks where the accuracy improvement justifies the financial outlay. Additionally, hardware architecture compatibility influences implementation feasibility. Certain scaling techniques require specialized tensor cores or memory bandwidth optimizations that may not be available across all deployment environments. The convergence of algorithmic flexibility and hardware constraints necessitates careful system-level design. Teams must prototype extensively to determine the optimal balance between runtime adaptability and infrastructure sustainability.
Monitoring infrastructure must evolve alongside scaling strategies to track resource utilization accurately. Engineers rely on telemetry dashboards to measure latency distributions, compute consumption per query, and accuracy degradation across different scaling tiers. These metrics inform continuous adjustments to routing policies and ensure that performance targets remain achievable under varying load conditions. The integration of automated optimization pipelines, similar to those discussed in Accelerating engineering cycles 20% with OpenAI, demonstrates how systematic monitoring reduces operational friction.
Looking Ahead: Practical Implications for Deployment
The trajectory of inference-time scaling points toward increasingly sophisticated runtime orchestration systems. Future architectures will likely incorporate automated difficulty classifiers that trigger scaling protocols without manual intervention. These classifiers will analyze prompt structure, historical query patterns, and real-time confidence scores to determine the appropriate computational allocation. Integration with existing engineering workflows will become critical as organizations scale their AI deployments. Teams that successfully merge dynamic compute management with continuous monitoring pipelines will achieve superior performance stability. This integration enables real-time adjustment of scaling parameters based on production feedback loops, ensuring that models maintain accuracy as data distributions shift.
The broader industry implications extend beyond individual model performance. Efficient inference scaling reduces the environmental footprint of large-scale AI operations by minimizing unnecessary computational waste. It also democratizes access to high-performance reasoning capabilities by allowing organizations to achieve stronger outputs without investing in exponentially larger static models. As hardware architectures evolve to support dynamic workload distribution, the boundary between training-time and inference-time optimization will continue to blur. Engineers who master these hybrid approaches will lead the next phase of practical AI deployment, focusing on sustainable, adaptable, and economically viable systems rather than raw parameter counts.
Long-term deployment success depends on aligning scaling strategies with organizational goals. Companies prioritizing rapid iteration will favor width scaling for its lower latency impact. Those emphasizing precision in regulated industries will lean toward depth scaling with rigorous verification loops. The flexibility to switch between modes based on operational context ensures that systems remain robust across diverse use cases.
Conclusion
The shift toward runtime compute allocation represents a fundamental rethinking of how artificial intelligence systems process information. Rather than viewing model capacity as a fixed ceiling, the industry now treats computational expenditure as a flexible resource directed toward high-return tasks. This paradigm encourages continuous optimization of deployment pipelines and fosters innovation in hardware-software co-design. Organizations prioritizing adaptive inference architectures will navigate the evolving landscape with greater resilience. The focus remains on delivering reliable reasoning capabilities while maintaining economic sustainability. As research progresses, dynamic scaling integration will become standard practice. Engineering teams must prepare for a future where compute allocation is managed with the same rigor as model architecture design.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)