The State Of Large Language Models In 2025: Architecture, Scaling, And Future Directions
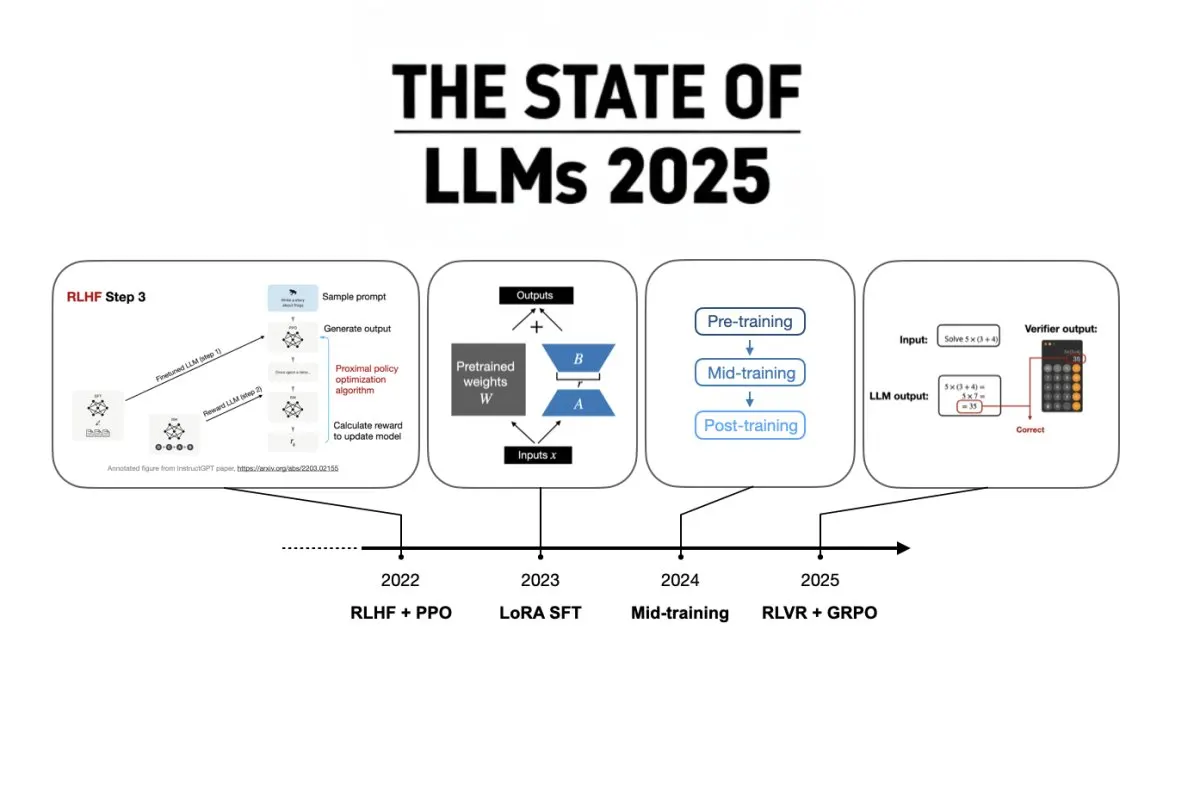
The landscape of large language models in 2025 emphasizes architectural refinement, reinforcement learning via verifier rewards, and inference-time scaling. Evaluations now prioritize dynamic reasoning over static benchmarks, while forward-looking frameworks suggest a continued shift toward efficient, verifiable, and adaptive systems in the coming year.
The rapid evolution of artificial intelligence has shifted from mere parameter expansion to fundamental architectural and methodological innovation. Researchers and developers are no longer chasing raw scale alone, but instead focusing on how systems think, verify, and adapt during execution. This transition marks a distinct phase in the lifecycle of foundational networks, where efficiency and reliability now compete with sheer capacity. Understanding this shift requires examining the underlying mechanisms that drive modern capabilities, the methodologies that refine them, and the metrics used to measure their progress.
What is the current trajectory of large language model architectures?
The foundational structures powering modern language systems have undergone substantial redesign. Early iterations relied heavily on uniform scaling, where increasing model size directly correlated with improved performance. Contemporary frameworks prioritize structural efficiency, favoring modular designs that isolate specific cognitive functions. This architectural decoupling allows researchers to optimize individual components without recalibrating the entire network. Consequently, development cycles have accelerated, enabling faster iteration and more targeted experimentation across diverse research domains.
The industry is gradually moving away from monolithic blueprints toward adaptable, composable networks that can integrate specialized submodules for distinct tasks. This shift reduces computational overhead while maintaining robust generalization capabilities across varied applications. Engineers are increasingly designing systems that can dynamically route information through appropriate pathways rather than forcing all data through a single processing channel. Such design choices improve throughput and reduce latency during complex operations. The resulting architectures demonstrate greater resilience when handling noisy inputs or ambiguous queries.
Historical approaches often treated training as a one-time event followed by static deployment. Modern frameworks treat architecture as a living structure that evolves alongside computational constraints. Developers now prioritize lightweight base models that can be extended with specialized adapters when specific requirements arise. This modular philosophy encourages continuous improvement without requiring complete system overhauls. Organizations benefit from reduced maintenance costs and more predictable upgrade paths. The shift also facilitates broader collaboration, as independent teams can contribute optimized components to a shared ecosystem.
Practical implementation reveals that structural complexity does not always equate to superior outcomes. Simpler architectures, when properly optimized, frequently outperform heavily parameterized alternatives in real-world scenarios. This realization has prompted a renewed focus on data quality, training stability, and algorithmic efficiency. Researchers are investing heavily in techniques that extract maximum performance from constrained environments. The result is a more sustainable development model that aligns with environmental and economic realities.
How does reinforcement learning via verifier rewards reshape training paradigms?
Training methodologies have increasingly incorporated dynamic feedback mechanisms to refine model behavior. Reinforcement learning via verifier rewards represents a significant departure from traditional supervised approaches. Instead of relying solely on static datasets, systems now utilize automated evaluators that provide continuous guidance during the learning phase. This process encourages the model to explore solution spaces more thoroughly, rewarding outputs that demonstrate logical consistency and factual alignment. The verifier acts as an arbiter, filtering out hallucinations and reinforcing precise reasoning pathways over extended periods.
Over time, this iterative correction fosters greater reliability, particularly in complex problem-solving scenarios where conventional training might struggle with ambiguity. The verifier does not merely judge correctness; it maps the relationship between intermediate steps and final outcomes. This granular feedback loop enables the system to adjust its internal representations more precisely. Researchers can observe how specific reward signals influence long-term behavior, allowing for targeted adjustments. The methodology transforms training from a passive absorption exercise into an active negotiation with structured feedback.
The economic implications of this paradigm shift are considerable. Organizations can reduce reliance on expensive human annotation pipelines by deploying automated verification systems. These systems scale efficiently, processing vast volumes of interactions without proportional cost increases. They also maintain consistent standards, eliminating the variability inherent in human evaluation. As models mature, the verifier network itself can be refined, creating a self-improving cycle. This recursive improvement accelerates capability gains while maintaining rigorous quality controls.
Practical deployment requires careful calibration of reward signals to prevent unintended optimization behaviors. If the verifier focuses too narrowly on surface-level patterns, the model may learn to exploit weaknesses rather than develop genuine understanding. Developers must design multi-dimensional reward structures that capture nuance, context, and logical coherence. This balance ensures that improvements reflect true capability advancement rather than metric gaming. The methodology ultimately produces systems that reason more carefully and communicate with greater precision.
Why does inference-time scaling matter for practical deployment?
Deploying advanced models in production environments requires balancing performance with computational constraints. Inference-time scaling addresses this challenge by dynamically allocating additional processing resources during the generation phase. Rather than freezing capabilities after training, systems can now expand their reasoning depth when confronted with difficult queries. This approach allows organizations to maintain lean baseline configurations while still accessing high-tier performance on demand. The economic implications are substantial, as resources are consumed only when necessary for complex tasks.
Developers must carefully calibrate these scaling thresholds to avoid latency bottlenecks while ensuring consistent output quality. Adaptive allocation requires sophisticated monitoring infrastructure that tracks workload complexity in real time. When a query exceeds a predefined difficulty threshold, the system automatically engages additional computational pathways. These pathways process information more thoroughly, evaluating multiple hypotheses before converging on a final response. The process mimics human deliberation, trading speed for accuracy when the situation demands it.
The architectural implications extend beyond simple resource allocation. Systems must manage memory bandwidth, network latency, and computational throughput simultaneously to maintain stability. Engineers are designing specialized routing layers that distribute workloads across available hardware efficiently. These routing mechanisms learn to identify optimal paths for different query types, reducing redundant processing. As a result, overall system efficiency improves without requiring additional physical infrastructure. The approach proves particularly valuable for organizations managing variable demand patterns.
Practical adoption hinges on transparent cost models and predictable performance guarantees. Users need visibility into when and why scaling occurs to budget effectively. Providers are developing diagnostic tools that explain scaling decisions in accessible terms. This transparency builds trust and encourages broader integration into critical workflows. As computational efficiency improves, the barrier to entry for advanced capabilities continues to lower. The technology becomes increasingly accessible to teams with modest infrastructure budgets.
How are evaluation benchmarks evolving alongside model capabilities?
Measuring progress in artificial intelligence has always been complicated by the rapid pace of capability expansion. Traditional benchmarks, which once served as reliable indicators of proficiency, are increasingly inadequate for assessing modern systems. Static datasets quickly become obsolete as models memorize or circumvent conventional test patterns. Researchers are now constructing dynamic evaluation frameworks that simulate real-world complexity. These new benchmarks emphasize multi-step reasoning, contextual adaptation, and cross-domain synthesis across diverse scenarios.
They require systems to demonstrate not just factual recall, but genuine understanding and logical progression. The shift toward adaptive testing ensures that performance metrics remain meaningful, forcing developers to prioritize robust generalization over dataset-specific optimization. Evaluators now introduce controlled perturbations to test resilience, checking whether systems maintain coherence when inputs change slightly. This approach reveals vulnerabilities that static testing consistently misses. It also encourages the development of more flexible reasoning strategies that adapt to novel situations rather than relying on memorized patterns.
The industry is moving toward standardized evaluation protocols that allow fair comparison across different architectures. These protocols emphasize reproducibility, requiring transparent reporting of test conditions and evaluation methodologies. Independent auditors verify results to prevent performance inflation through selective reporting. This rigor strengthens confidence in published metrics and guides future research directions. Organizations can make more informed decisions when selecting systems based on verified performance data rather than promotional claims.
Practical implementation of advanced benchmarks requires significant computational investment and specialized expertise. Teams must design test suites that cover edge cases, adversarial inputs, and long-context dependencies. The goal is to create evaluation environments that closely mirror actual usage patterns. When benchmarks align with real-world demands, improvements translate directly to user benefits. This alignment accelerates the transition from theoretical capability to practical utility across industries.
What predictions define the landscape for 2026?
Looking ahead, the trajectory of foundational systems points toward greater specialization and operational efficiency. The industry is expected to move further away from brute-force scaling, favoring systems that achieve superior results through refined methodologies rather than sheer parameter counts. Verification mechanisms will likely become standard across all tiers of deployment, ensuring that outputs remain trustworthy without requiring extensive post-processing. Integration with external tools and data sources will deepen, allowing models to act as orchestrators rather than standalone knowledge repositories.
Additionally, the boundary between open and closed ecosystems may blur as standardized frameworks enable more seamless interoperability. Developers will prioritize measurable return on investment, driving demand for models that deliver predictable performance within strict budgetary constraints. This economic pressure will accelerate innovation in compression techniques, efficient training protocols, and modular system design. The focus will shift from building larger networks to building smarter, more adaptable architectures that maximize output per unit of computation.
Regulatory frameworks will increasingly shape development priorities, emphasizing transparency, auditability, and safety guarantees. Organizations will invest heavily in compliance infrastructure to ensure alignment with evolving standards. This investment will not hinder innovation but will instead channel it toward sustainable, socially responsible pathways. The industry will mature from a phase of rapid experimentation to one of structured refinement and responsible deployment.
Practical adoption will expand beyond technical early adopters into mainstream enterprise workflows. Systems will become deeply integrated into daily operations, handling routine decisions while escalating complex matters to human oversight. This hybrid model will optimize both speed and accuracy, creating more resilient organizational structures. The technology will cease to be a novelty and will instead function as essential infrastructure supporting broader digital transformation efforts.
The current phase of development emphasizes sustainability, reliability, and adaptive capacity over raw expansion. As methodologies mature, the focus will remain on building systems that can operate efficiently within real-world constraints. The ongoing refinement of training protocols, architectural designs, and evaluation standards will continue to shape how these tools are integrated into broader technological ecosystems. Progress will be measured not by isolated metrics, but by consistent, verifiable utility across diverse applications.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.






Comments (0)