OpenAI Updates ChatGPT Default Model With GPT-5.5 Instant
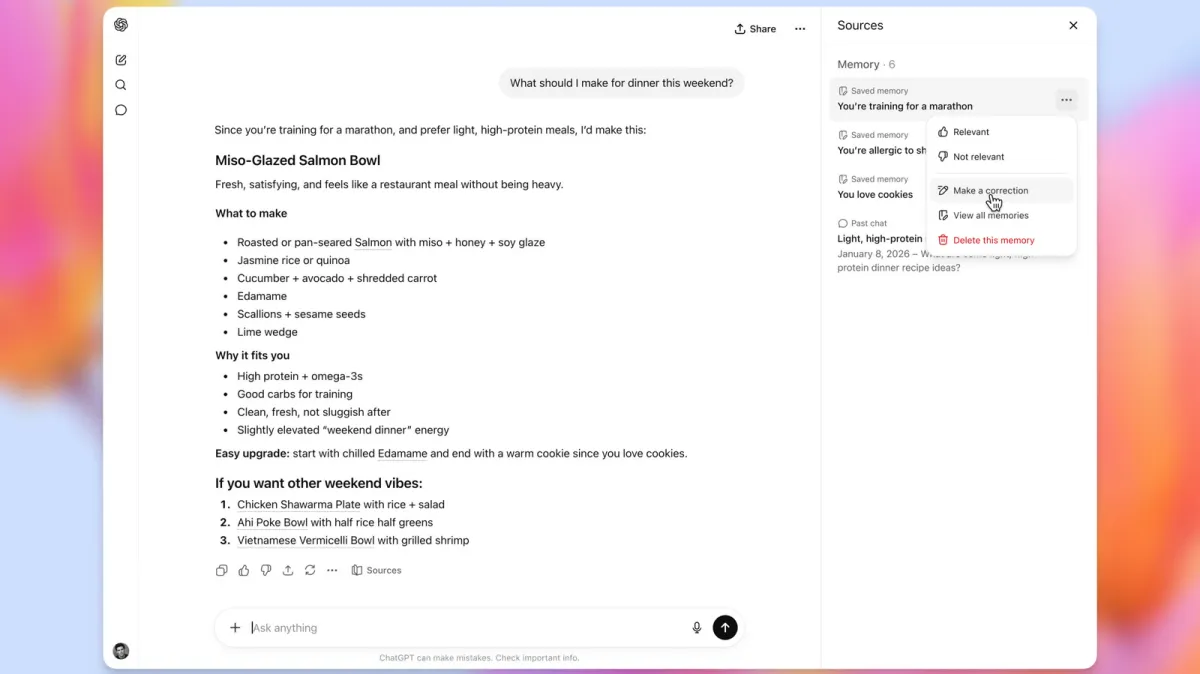
OpenAI has updated ChatGPT's default model to GPT-5.5 Instant, claiming substantial reductions in hallucinated and inaccurate claims during internal testing. The update prioritizes direct responses, reduced clutter, and improved personalization through faster context retrieval. A new memory sources feature provides visibility into used data, with a phased rollout across subscription tiers.
The landscape of conversational artificial intelligence shifts rapidly as developers refine how machines process, retain, and deliver information. OpenAI recently announced a significant update to its flagship platform, transitioning the default engine to a new architecture designed to address long-standing criticisms regarding accuracy and contextual awareness. This transition marks a deliberate pivot toward reducing fabricated information while enhancing the system's ability to recall user-specific data. The update introduces measurable improvements in factual reliability and introduces new mechanisms for managing personal context.
What is GPT-5.5 Instant and how does it change the default experience?
The transition to GPT-5.5 Instant represents a foundational adjustment to how the platform handles routine queries and complex prompts alike. OpenAI designed this iteration to function as the primary engine for daily interactions, replacing previous default architectures that prioritized raw generation speed over contextual precision. The engineering team focused on restructuring the underlying token prediction pathways to minimize speculative output. By tightening the constraints around factual alignment, the system now filters responses through stricter verification protocols before delivery. This architectural shift aims to reduce the cognitive load required from users who must constantly fact-check generated content. The change reflects a broader industry movement toward reliability over novelty in consumer-facing artificial intelligence tools.
Developers have also recalibrated the interface to support more efficient workflows. The new model generates more direct answers while preserving the conversational warmth that defines the platform. Unnecessary follow-up questions that previously fragmented dialogue flow have been systematically reduced. Output formatting has been streamlined to eliminate visual clutter, including a deliberate reduction in decorative emoji usage. These refinements collectively create a more professional and efficient interaction model. Users will notice that responses arrive with greater structural clarity and fewer redundant conversational fillers. The platform now emphasizes precision and readability as primary design metrics.
This shift away from novelty-driven updates signals a mature phase in large language model development. Early iterations focused heavily on expanding vocabulary and creative capabilities. The current generation prioritizes stability and trustworthiness as core requirements. Engineers recognize that users abandon platforms that fail to deliver consistent results. By establishing GPT-5.5 Instant as the default, OpenAI ensures that reliability becomes the baseline experience rather than an optional premium feature. This strategic decision aligns with broader market expectations for enterprise-grade performance.
Why does factual accuracy matter in conversational AI?
The pursuit of factual reliability has become the central challenge for large language model developers. Early iterations of conversational systems frequently generated plausible but incorrect information, a phenomenon widely recognized as hallucination. This issue undermines user trust and limits practical utility in professional or academic environments. OpenAI's internal testing indicates that the new default model produces fifty-two point five percent fewer hallucinated claims compared to its predecessor. When evaluated against conversations previously flagged by users for containing inaccuracies, the system demonstrates a thirty-seven point three percent reduction in false statements. These metrics highlight a substantial improvement in the model's grounding mechanisms.
Achieving this level of accuracy requires continuous refinement of retrieval-augmented generation techniques. The model must distinguish between verified knowledge and speculative pattern matching during inference. Engineers have implemented stricter alignment protocols that penalize confident but unsupported assertions. The system now cross-references internal knowledge bases more rigorously before committing to a specific claim. This process slows down raw generation speed slightly but drastically improves the reliability of the output. Users benefit from responses that are more carefully vetted and less prone to drifting into fabricated territory.
The implications extend beyond simple error reduction. When artificial intelligence systems provide accurate information, they become viable tools for decision-making, research assistance, and creative development. Inaccurate outputs force users to invest additional time verifying results, which negates the efficiency gains promised by automation. By prioritizing factual correctness, OpenAI aligns the platform with professional standards that demand verifiable information. This approach also reduces the risk of misinformation spreading through automated channels. The industry recognizes that trust is the foundation of widespread adoption.
Economic factors further emphasize the importance of accuracy in commercial applications. Businesses cannot afford to deploy assistants that generate unverified claims during client interactions or internal documentation. The financial cost of correcting AI errors often exceeds the initial subscription price. Developers must therefore balance computational efficiency with rigorous quality control measures. The new default model demonstrates that accuracy improvements do not require prohibitive infrastructure costs. Optimized retrieval pathways and refined training objectives can deliver substantial gains without compromising accessibility.
How does personalized context reshape user interaction?
Personalization has emerged as a critical differentiator in the competitive artificial intelligence market. Users expect systems to remember preferences, past interactions, and specific project details without requiring constant repetition. The updated architecture accelerates the retrieval of uploaded documents, connected email accounts, and historical conversation logs. This enhanced processing speed allows the model to synthesize relevant information much faster than previous versions. The result is a dialogue that feels more continuous and contextually aware. Individuals will find that they no longer need to restate foundational details for every new session.
To address privacy concerns surrounding personalized data, OpenAI introduced a feature called memory sources. This component provides users with transparent visibility into the specific information the system utilized to generate a particular response. The interface allows individuals to review, update, or delete stored context items that are no longer relevant. Users retain complete authority over their data footprint. The platform explicitly states that memory sources remain hidden when chats are shared externally. This design ensures that personal context does not leak into public or collaborative spaces.
The implementation of memory sources reflects a broader industry shift toward user-controlled data management. As artificial intelligence systems become more integrated into daily workflows, the boundary between personal history and automated processing grows increasingly porous. Providing transparent controls helps maintain user confidence. The current iteration does not display every single data point used during inference, but development teams are actively working to expand this visibility. Future updates will likely provide more granular insights into how personal context influences generated outputs. This transparency is essential for building long-term trust with enterprise and individual users alike.
Cross-device synchronization presents additional technical challenges for personalized assistants. Managing consistent context across multiple platforms requires robust indexing mechanisms and secure data transmission protocols. The engineering teams must ensure that memory updates propagate reliably without introducing latency or security vulnerabilities. As seen in recent developments surrounding next-gen Siri integration and cross-platform assistant ecosystems, synchronizing personal data remains a complex engineering hurdle. OpenAI's phased rollout allows the company to monitor synchronization stability before expanding to broader user bases. This cautious approach minimizes the risk of widespread data inconsistencies.
What are the broader implications for AI assistants?
The strategic rollout of these updates reveals important insights about the current state of artificial intelligence development. OpenAI is deploying the enhanced personalization capabilities to Plus and Pro subscribers first, while Free, Go, Business, and Enterprise tiers will receive access in subsequent phases. This tiered distribution strategy allows the company to monitor system stability and gather performance data from high-engagement users before expanding to the broader population. The memory sources feature will eventually reach all users across web and mobile platforms, signaling a commitment to universal data transparency.
The deployment timeline also highlights the technical complexity involved in scaling personalized retrieval systems. Managing vast amounts of user-specific context requires robust infrastructure and efficient indexing mechanisms. As more individuals connect external data sources like email and document repositories, the computational demands increase exponentially. The engineering teams must balance speed, accuracy, and privacy while maintaining consistent performance across diverse hardware configurations. This challenge is common across the sector, as seen in recent developments surrounding Apple TV and HomePod mini refresh signals and integrated assistant ecosystems.
Looking ahead, the emphasis on factual accuracy and contextual memory will likely dictate the next generation of intelligent assistants. Competitors will need to match these reliability standards while offering comparable personalization features. The industry is moving away from novelty-driven updates toward utility-focused refinements. Users increasingly demand tools that function reliably in professional environments rather than serving primarily as entertainment platforms. The success of this new default model will depend on sustained performance improvements and consistent privacy protections. As artificial intelligence continues to integrate into daily workflows, the distinction between helpful assistance and speculative generation will become even more critical.
Enterprise adoption will ultimately determine the long-term viability of these features. Organizations require strict compliance frameworks and audit trails before integrating AI assistants into critical operations. The memory sources feature provides a necessary foundation for data governance and regulatory compliance. By giving users explicit control over stored context, OpenAI addresses a major barrier to corporate deployment. The platform's ability to maintain transparency while delivering personalized utility will set a benchmark for future industry standards.
Conclusion
The transition to GPT-5.5 Instant marks a deliberate step toward more reliable and context-aware artificial intelligence. By prioritizing factual accuracy, streamlining response formatting, and introducing transparent memory controls, the platform addresses longstanding user concerns. The phased rollout demonstrates a cautious approach to scaling personalized features across diverse subscription tiers. As the technology matures, the focus will remain on delivering consistent utility while maintaining strict data governance. The long-term success of conversational AI depends on balancing innovation with verifiable performance and user trust.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.








Comments (0)