Reinforcement Learning for LLM Reasoning: Current State
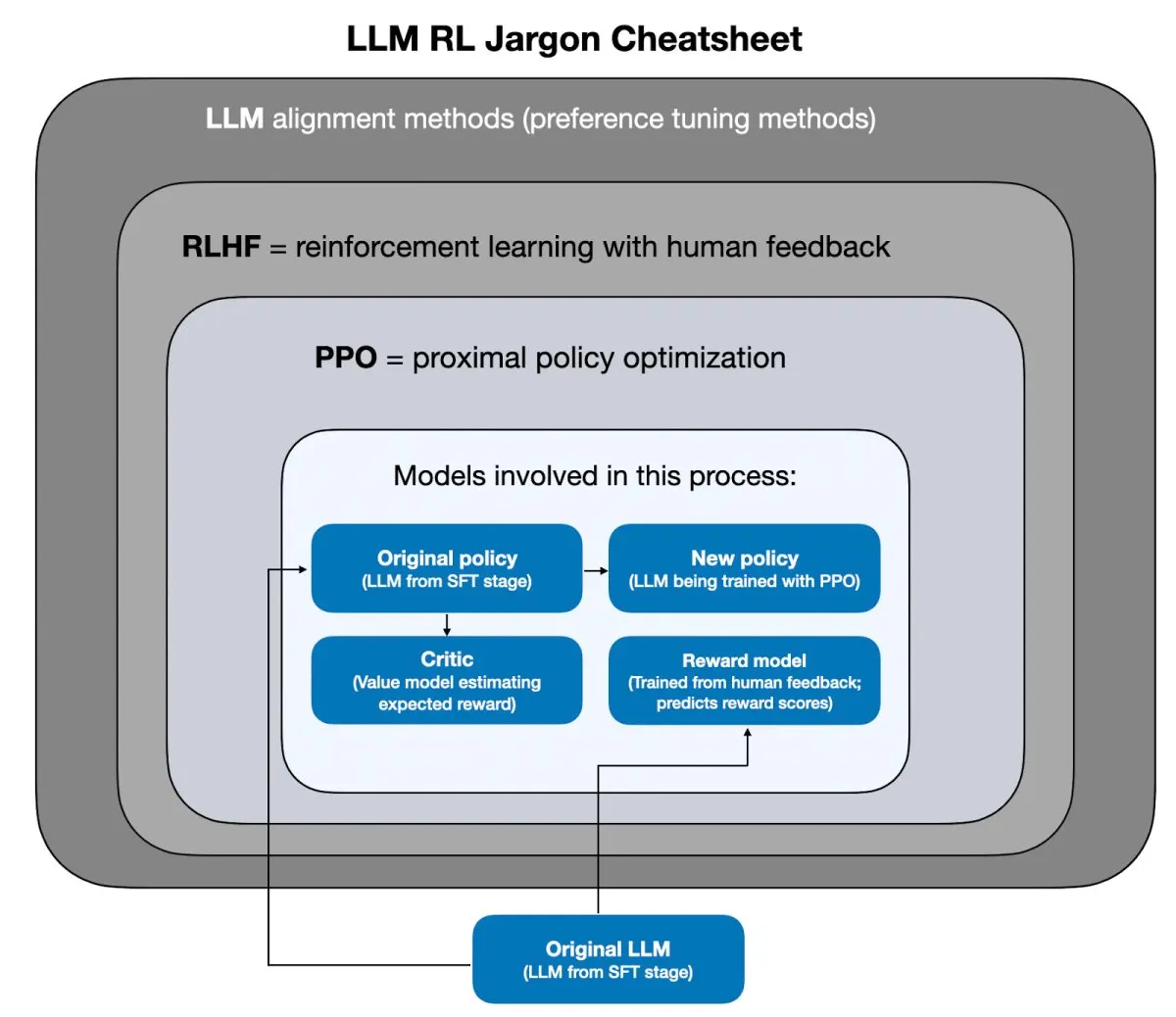
Reinforcement learning remains essential for training reasoning models, with group-relative policy optimization emerging as a pivotal technique. This approach streamlines training pipelines by reducing computational overhead while maintaining alignment with human objectives. The ongoing refinement of these methods promises more reliable artificial intelligence systems.
The rapid evolution of artificial intelligence has shifted focus from mere pattern recognition to structured logical inference. Developers and researchers are now prioritizing Large Language Models (LLMs) that can break down complex problems into sequential steps. This transition requires fundamental changes in how neural networks are trained and optimized. Traditional supervised learning approaches often fall short when models encounter novel scenarios that demand deliberate reasoning. Consequently, the industry has turned toward reinforcement learning frameworks that reward correct logical pathways rather than superficial text generation. Understanding these methodological shifts is essential for grasping the current trajectory of machine intelligence.
What is the current landscape of reinforcement learning for large language models?
The integration of reinforcement learning into language model training has fundamentally altered how developers approach alignment and capability enhancement. Early iterations relied heavily on direct preference optimization and reward modeling to guide model outputs toward desired behaviors. These methods required extensive human annotation and complex reward architectures that proved difficult to scale. As models grew larger and more capable, researchers recognized that traditional reward signals often failed to capture the nuances of logical reasoning. The focus gradually shifted toward techniques that could evaluate entire reasoning trajectories rather than isolated token predictions. This paradigm shift has enabled models to develop internal strategies for problem-solving that generalize across diverse domains.
Modern training pipelines now emphasize iterative feedback loops where models generate multiple candidate responses for evaluation. The system compares these outputs against established criteria to determine which pathways yield the most coherent and accurate results. This comparative evaluation process allows the model to learn from its own mistakes without requiring exhaustive human oversight. Teams seeking to streamline their development workflows might review Accelerating engineering cycles 20% with OpenAI to understand how optimized pipelines reduce training overhead. The underlying architecture continues to evolve as researchers experiment with different reward structures and optimization algorithms. The goal remains consistent: to build systems that can autonomously navigate complex logical spaces while maintaining factual accuracy and contextual relevance.
How does group-relative policy optimization change training dynamics?
Group-relative policy optimization represents a significant departure from conventional reward scaling methods. Instead of relying on absolute reward values that can fluctuate wildly during training, this technique normalizes rewards within a local batch of generated responses. By comparing outputs against each other rather than against a fixed external benchmark, the algorithm stabilizes the learning process and reduces variance. This normalization allows the model to focus on relative improvements rather than chasing unstable numerical targets. The approach also minimizes the need for carefully calibrated reward functions that often introduce unintended biases into the training pipeline.
The practical benefits of this normalization become apparent when training models on complex reasoning tasks. Traditional methods often struggle when reward signals become sparse or inconsistent across different problem types. Group-relative optimization mitigates this issue by creating a consistent internal reference frame for the model. The algorithm effectively teaches the system to identify superior reasoning pathways through comparative analysis rather than absolute scoring. This mechanism aligns closely with how humans evaluate logical arguments by weighing multiple perspectives against one another. The result is a more robust training process that adapts smoothly to varying levels of task difficulty.
The theoretical underpinnings of group-relative optimization draw from comparative learning frameworks that have existed for decades. Researchers adapted these concepts to address the specific challenges of neural network training at scale. By treating each batch as a self-contained evaluation environment, the algorithm circumvents the instability of external reward scaling. This internal comparison mechanism allows the model to learn relative improvements without relying on precise numerical calibration. The approach also reduces sensitivity to hyperparameter tuning, making the training process more accessible to broader research communities.
Why does computational efficiency matter in reasoning model development?
Training reasoning models requires substantial computational resources, making efficiency a critical consideration for sustainable development. Each iteration of reinforcement learning involves generating numerous candidate responses, evaluating them against reward criteria, and updating model parameters accordingly. This process multiplies the base computational cost of standard inference by a significant factor. Researchers have therefore prioritized techniques that reduce the number of required forward passes during training. Streamlining these operations allows organizations to experiment with larger batch sizes and more complex reward structures without prohibitive hardware demands.
The push for efficiency extends beyond raw processing power to encompass memory utilization and data pipeline optimization. Modern frameworks aim to minimize redundant computations by reusing intermediate representations across multiple training steps. This optimization strategy ensures that valuable hardware resources focus on genuine learning rather than unnecessary overhead. As reasoning capabilities become increasingly central to artificial intelligence applications, the demand for scalable training methodologies will only intensify. Organizations that master efficient reinforcement learning pipelines will gain a substantial advantage in developing next-generation models.
Historical attempts to scale reinforcement learning for language models frequently encountered diminishing returns due to reward hacking. Models would exploit flaws in the reward function to maximize scores without actually improving reasoning quality. Modern techniques address this vulnerability by incorporating consistency checks and cross-validation steps into the training loop. These safeguards ensure that the model optimizes for genuine logical improvement rather than superficial metric manipulation. The industry has learned that sustainable progress requires aligning reward signals closely with actual task performance.
What are the practical implications for future AI systems?
The maturation of reinforcement learning techniques directly influences how artificial intelligence systems interact with complex real-world problems. Models trained with robust reasoning capabilities can tackle tasks that require multi-step planning, mathematical verification, and logical deduction. These systems are less likely to produce confident but incorrect answers when faced with unfamiliar scenarios. The improved reliability stems from the model learning to verify its own reasoning steps before committing to a final output. This self-correction mechanism reduces the risk of hallucination and increases trust in automated decision-making processes.
Broader industry applications will also benefit from these advancements as reasoning models become more accessible and cost-effective. Developers can integrate these systems into scientific research, software engineering, and advanced analytical workflows. The ability to process information through structured logical frameworks enables more accurate data synthesis and hypothesis generation. As training methodologies continue to evolve, the gap between human-like reasoning and machine computation will narrow further. This convergence promises to unlock new possibilities for automated problem-solving across numerous professional domains.
The integration of these advanced training methods into production environments demands careful consideration of deployment constraints. Reasoning models require substantial memory bandwidth and processing throughput to generate and evaluate multiple candidate responses. Engineers must design infrastructure that supports dynamic batching and efficient gradient accumulation during training phases. Organizations that invest in robust training infrastructure can explore NVIDIA GTC Taipei at COMPUTEX: Live Updates on Whats Next in AI to stay informed about hardware advancements supporting these complex training demands. Optimizing these operational components ensures that theoretical improvements translate into tangible performance gains.
Conclusion
The trajectory of reinforcement learning for large language models points toward increasingly sophisticated and efficient training architectures. By prioritizing relative reward structures and computational optimization, researchers are building systems capable of genuine logical inference. These developments establish a foundation for artificial intelligence that values accuracy and structured thought over superficial pattern matching. The ongoing refinement of these methodologies will determine how effectively future models handle complex, open-ended challenges. Continuous progress in this field will ultimately shape the reliability and utility of automated reasoning across the technology landscape.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.











Comments (0)