Understanding the KV Cache in Large Language Models
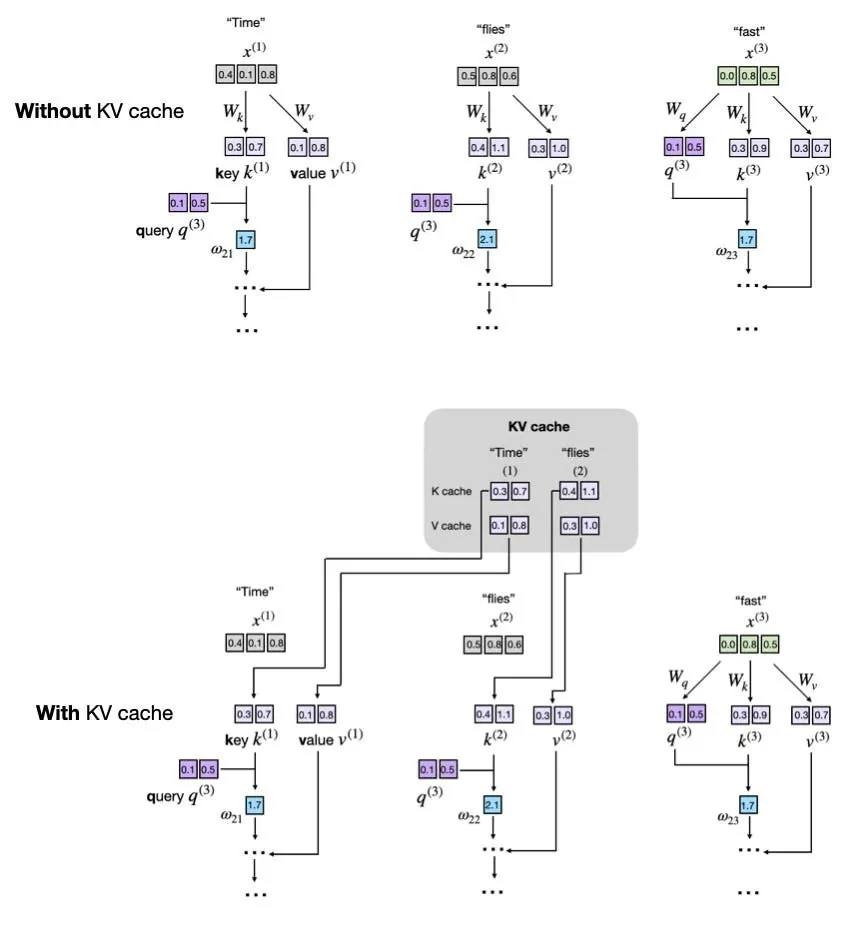
The key-value cache serves as a fundamental optimization mechanism for large language model inference. By storing previously computed attention weights, it eliminates redundant calculations, significantly reduces memory bandwidth requirements, and enables faster token generation during real-time applications.
Large language models generate text by processing sequences of tokens through complex mathematical operations. Each new token requires evaluating relationships with every preceding token in the sequence. This sequential evaluation creates a substantial computational burden that grows exponentially with context length. Engineers have developed specific architectural solutions to address this scaling challenge. The key-value cache represents one of the most effective mechanisms for managing this computational load during active inference.
What Is the Key-Value Cache in Large Language Models?
The attention mechanism forms the mathematical foundation of transformer architectures. During the initial processing phase, the model calculates query, key, and value vectors for every token in the input sequence. These vectors determine how much focus the model should place on different parts of the text when generating subsequent outputs. The key-value cache captures these computed vectors after the initial forward pass. Instead of recalculating them for each new token, the system retrieves the stored values directly from memory. This approach transforms a quadratic complexity problem into a linear one.
The distinction between training and inference workflows explains why this optimization matters. Training requires processing entire sequences simultaneously to update model weights through backpropagation. Inference generates tokens sequentially, one at a time, responding to user prompts in real time. Each new token addition would normally trigger a complete recalculation of attention scores across the entire context window. The cache intercepts this redundant computation by preserving intermediate results. Engineers rely on this preservation to maintain consistent response times as conversation length increases.
How Does the Key-Value Cache Reduce Computational Overhead?
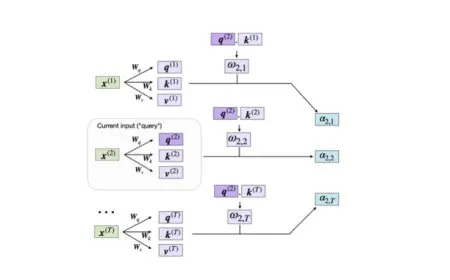
Memory access patterns dictate the performance limits of modern inference systems. Processing a new token requires comparing it against every previous token in the sequence. Without cached intermediates, the system must repeatedly fetch raw input embeddings and recompute attention matrices from scratch. This repeated computation consumes substantial processing cycles and drains available memory bandwidth. The cache stores the key and value projections for all preceding tokens in a dedicated memory buffer. Subsequent token generations simply append new projections to this buffer and read existing entries. This direct retrieval bypasses expensive matrix multiplications.
The architectural design of the cache aligns with how modern processors handle temporal locality. Systems that keep frequently accessed data close to the compute units experience dramatically faster response times. The key-value cache operates on the same principle by maintaining active context data in high-speed memory regions. When the model evaluates attention scores, it pulls cached keys and values directly from this optimized storage layer. The computational graph shrinks significantly because the system no longer needs to reconstruct intermediate representations. This reduction in workload allows hardware to focus on actual matrix operations rather than redundant data preparation.
The Mechanics of Attention and Memory Storage
Attention scores determine how much weight the model assigns to different parts of the input. Each score represents a mathematical relationship between the current query vector and a stored key vector. The resulting weighted sum of value vectors produces the contextual output for that position. Storing these intermediate results requires careful memory management. The cache must accommodate variable sequence lengths while maintaining strict alignment with the model architecture. Engineers implement dynamic allocation strategies to handle different batch sizes and context windows. The storage structure typically mirrors the transformer layer configuration to ensure seamless data flow.
Why Does Memory Bandwidth Matter for Inference Latency?
Computational throughput often receives the most attention in hardware discussions, but memory bandwidth frequently becomes the actual bottleneck. Large language models contain billions of parameters that must move between storage layers during every generation step. When the system lacks cached intermediates, it must continuously stream raw embeddings and intermediate activations through narrow memory channels. This constant data movement saturates available bandwidth and stalls compute units. The cache mitigates this bottleneck by keeping active context data readily accessible. Reduced data movement translates directly to lower latency and higher token throughput.
Modern data center architectures prioritize memory hierarchy optimization to address these constraints. Engineers design specialized memory controllers that prioritize cache hits over raw parameter fetching. The system can sustain higher request volumes when it minimizes long-distance memory access. This optimization becomes particularly critical during peak usage periods when multiple inference requests compete for shared resources. Efficient cache utilization ensures that compute units remain active rather than waiting for data retrieval. The resulting performance gains allow production systems to handle larger context windows without proportional hardware upgrades.
How Do Production Systems Leverage Cache Optimization?
Deploying large language models in real environments requires balancing accuracy with resource efficiency. Engineers implement cache management protocols that align with specific hardware capabilities and workload patterns. The system monitors memory utilization metrics to determine when to evict older context entries or compress stored projections. These management decisions directly impact response quality and system stability. Production pipelines often incorporate dynamic cache sizing to accommodate fluctuating request volumes. The architecture must adapt to varying sequence lengths without triggering memory exhaustion or performance degradation.
Infrastructure teams frequently evaluate accelerating engineering cycles to optimize deployment pipelines and streamline cache integration workflows. The integration process involves mapping model layers to memory allocation schemes and establishing clear data flow boundaries. Engineers test different cache configurations under realistic load conditions to identify optimal memory utilization thresholds. These tests reveal how different sequence lengths affect overall system responsiveness. The resulting configurations provide clear guidelines for scaling inference workloads across distributed hardware clusters.
Quantization and Cache Management Strategies
Reducing numerical precision represents another approach to managing cache memory requirements. Lower precision formats decrease the storage footprint of key and value projections while maintaining acceptable accuracy levels. The system applies quantization algorithms that map high-precision values to compressed representations. These compressed entries occupy less memory bandwidth during retrieval operations. Engineers carefully calibrate quantization parameters to prevent accuracy degradation during complex reasoning tasks. The balance between compression ratio and computational fidelity determines the practical limits of cache optimization.
Cache eviction policies determine which context entries remain active during extended conversations. Systems prioritize recent tokens because they carry the highest contextual relevance for immediate predictions. Older entries receive lower priority and may be compressed or removed to free memory space. This prioritization mirrors how human working memory handles information retention. The model maintains focus on immediate context while discarding less relevant historical data. Engineers implement sliding window techniques to enforce these boundaries automatically. The resulting architecture supports extended interactions without exhausting available memory resources.
The historical development of transformer architectures highlights the necessity of these optimizations. Early implementations processed sequences without intermediate caching, resulting in severe performance degradation as context expanded. Researchers identified the quadratic scaling problem and proposed caching strategies to isolate redundant calculations. This discovery shifted engineering priorities toward memory-aware algorithm design. Modern frameworks now treat cache management as a core component of model execution rather than an optional enhancement. The evolution demonstrates how theoretical constraints directly shape practical system architecture.
Distributed inference environments introduce additional complexity to cache management protocols. Multiple compute nodes must synchronize memory states to maintain consistent context across parallel requests. Engineers develop specialized communication protocols that replicate cache entries across clusters while minimizing network overhead. These protocols ensure that token generation remains synchronized regardless of physical hardware distribution. The system dynamically routes requests to nodes with available cache space. This load balancing mechanism prevents memory bottlenecks and maintains uniform response times across the entire deployment.
The optimization of inference workflows continues to evolve as model architectures grow more complex. Engineers refine cache management techniques to extract maximum performance from existing hardware constraints. The focus remains on reducing redundant computation while preserving the mathematical integrity of attention mechanisms. Production systems that implement these optimizations deliver faster responses and lower operational costs. The underlying principles of memory efficiency and computational reuse will guide future developments in large language model infrastructure.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)