LLM Research Trends and Architectural Shifts in Early 2025
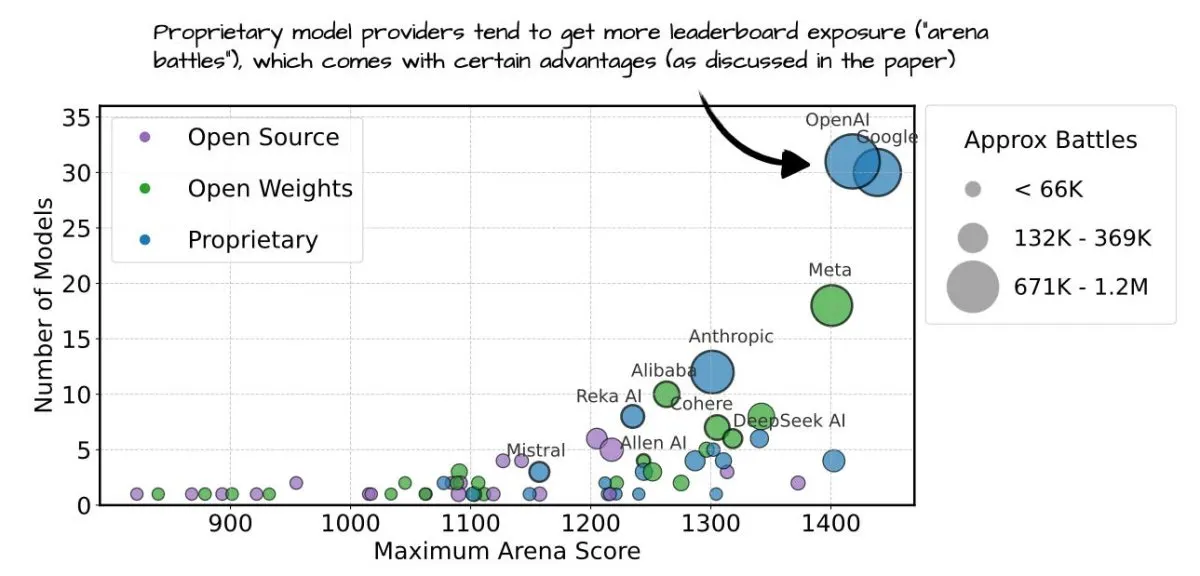
The first half of 2025 reveals a decisive industry shift toward architectural efficiency, refined evaluation methodologies, and sustainable scaling practices. Researchers are prioritizing modular designs and open-weight ecosystems to improve real-world utility while reducing computational overhead.
The rapid progression of artificial intelligence has fundamentally altered how researchers approach foundational models. The early months of 2025 have witnessed a distinct pivot away from sheer parameter expansion toward more sustainable and targeted innovations. Scholars and engineers are now prioritizing architectural refinement, computational efficiency, and robust evaluation frameworks. This shift reflects a mature understanding that scaling alone no longer guarantees meaningful capability gains. The current landscape demands a deeper examination of how these developments are reshaping the trajectory of machine learning and guiding future investment.
What is the current trajectory of large language model research?
The field has moved beyond the initial phase of relentless scaling. Early in the year, academic and industrial laboratories began emphasizing sustainable growth over brute force expansion. Researchers recognized that diminishing returns were becoming apparent when simply adding more parameters to existing transformer structures. Instead, the focus has shifted toward optimizing data quality, improving training algorithms, and refining architectural components. This transition marks a necessary evolution in how foundational models are conceived and deployed. The community is now investing heavily in methods that extract greater capability from existing computational budgets while maintaining strict quality standards.
Why does architectural efficiency matter more than raw scale?
Computational constraints have forced a reevaluation of traditional design paradigms. Large models require substantial infrastructure, which limits accessibility and increases environmental impact. Engineers are now exploring sparse activation patterns, where only a fraction of parameters activates during inference. This approach dramatically reduces memory requirements and accelerates response times without sacrificing performance. The industry is also examining alternative attention mechanisms that bypass quadratic complexity. These structural adjustments allow organizations to deploy capable systems on more accessible hardware. The pursuit of efficiency has become a central pillar of modern research and operational strategy.
The shift toward modular and hybrid architectures
Researchers are increasingly combining specialized components to create flexible systems. Modular designs allow different parts of a model to handle distinct tasks or modalities. This strategy improves maintainability and enables targeted updates without retraining entire networks. Hybrid approaches blend dense and sparse techniques to balance speed with capacity. These architectural choices reflect a broader understanding that flexibility outperforms monolithic scaling. Organizations are also experimenting with routing mechanisms that dynamically allocate computational resources. The goal remains consistent: achieve higher performance while minimizing operational costs.
How are evaluation metrics evolving beyond benchmark scores?
Traditional testing frameworks have shown clear limitations in predicting real-world performance. Early benchmark scores often failed to capture nuances like reasoning stability, factual consistency, or task adaptability. Researchers are now developing dynamic evaluation pipelines that test models across diverse, continuously shifting scenarios. These new methods prioritize robustness and generalization over static test results. The community recognizes that models must demonstrate reliability across edge cases and novel inputs. Evaluation is becoming less about passing fixed exams and more about proving sustained capability in unpredictable environments. This change fundamentally alters how progress is measured and how resources are allocated across teams.
Rethinking generalization and real-world utility
The gap between controlled benchmarks and practical application has widened significantly. Models that excel on curated datasets often struggle when confronted with noisy, unstructured data. Researchers are addressing this by incorporating adversarial testing and stress-testing protocols into standard validation routines. These practices reveal failure modes that static evaluations conceal. Additionally, there is a growing emphasis on interpretability and transparency during the assessment phase. Understanding how a model arrives at a conclusion is now considered as important as the conclusion itself. This shift ensures that deployed systems remain trustworthy and auditable.
What implications do open-weight models hold for the ecosystem?
The proliferation of openly available model weights has transformed the research landscape. Developers no longer need to rely solely on proprietary APIs to experiment with cutting-edge architectures. This accessibility accelerates innovation by allowing independent researchers to build upon existing work. It also fosters transparency, as the community can audit models for biases and safety concerns. However, this openness introduces new responsibilities regarding responsible distribution and usage guidelines. Organizations are balancing the benefits of collaboration with the need to maintain quality control. The open-weight movement continues to drive rapid iteration and cross-pollination of ideas across academic and commercial sectors worldwide.
How is data curation influencing model capability?
The quality of training data now outweighs the quantity of parameters. Researchers have discovered that poorly curated datasets introduce noise that degrades reasoning capabilities. Efforts are concentrated on filtering, deduplication, and synthetic data generation to create cleaner training corpora. This focus ensures that models learn accurate patterns rather than memorizing artifacts. The community is also prioritizing diverse linguistic representations and cross-domain knowledge. By refining the foundational material, engineers can improve generalization without expanding model size. Data strategy has become as critical as algorithm design and infrastructure planning.
Strategies for building robust training corpora
Organizations are implementing rigorous pipeline standards to verify data provenance and relevance. Automated filtering tools help remove low-quality content before it enters the training loop. Human-in-the-loop verification remains essential for assessing nuanced contexts and cultural accuracy. These processes reduce the risk of propagating misinformation or harmful biases. Researchers are also experimenting with curriculum learning techniques that gradually increase dataset complexity. This approach mimics natural learning pathways and improves long-term retention. The emphasis on data integrity reflects a broader commitment to building reliable foundations.
What role does multimodal integration play in future development?
The boundary between text and other data types is rapidly dissolving. Early efforts focused on simply appending image or audio encoders to existing language models. Current research emphasizes tight coupling, where modalities inform each other during training. This integration allows systems to reason across different input formats with greater coherence. Researchers are exploring cross-attention mechanisms that align semantic structures across visual, auditory, and textual streams. The goal is to create unified representations that capture complex real-world interactions. Multimodal alignment is becoming a prerequisite for practical deployment and widespread adoption.
Challenges in cross-modal alignment
Synchronizing different data types requires sophisticated architectural adjustments. Misalignment often leads to contradictory outputs when the model processes conflicting signals. Engineers are developing specialized loss functions that penalize inconsistencies between modalities. These techniques force the network to learn shared underlying concepts rather than treating each input independently. Additionally, researchers are investigating dynamic routing strategies that determine which modality should dominate a given context. This flexibility improves robustness and reduces error rates. The pursuit of seamless integration remains a central challenge.
How are organizations optimizing compute resources for training?
Computational efficiency has become a primary driver of architectural decisions. Researchers are exploring mixed precision training and gradient checkpointing to reduce memory footprints. These techniques allow larger batch sizes to be processed without exceeding hardware limits. Engineers are also investigating compiler optimizations that streamline kernel execution on specialized accelerators. The industry recognizes that maximizing hardware utilization is essential for maintaining research velocity. Optimizing the training pipeline directly impacts the speed of iteration and the feasibility of large-scale experiments. Efficiency gains compound across every stage of development and deployment pipelines.
Practical approaches to hardware utilization
Data parallelism and tensor parallelism are being combined to distribute workloads effectively. Researchers are designing custom topologies that minimize communication overhead between processing units. Load balancing algorithms ensure that each accelerator contributes equally to the training process. These structural optimizations reduce idle time and improve overall throughput. Additionally, there is growing interest in fault-tolerant training methods that handle hardware failures gracefully. This resilience prevents costly interruptions and preserves computational investments. The focus on infrastructure efficiency supports more ambitious research objectives.
What practical takeaways emerge from recent research trends?
The current landscape offers clear guidance for practitioners and organizations. Investing in data quality yields higher returns than scaling parameters indefinitely. Adopting modular architectures enables faster iteration and easier maintenance across diverse use cases. Implementing dynamic evaluation frameworks provides a more accurate measure of real-world readiness. These strategies collectively reduce risk while accelerating the path to deployment. Teams that prioritize efficiency and robustness will likely maintain a competitive advantage. The industry is moving toward sustainable, scalable development practices that prioritize long-term viability.
Aligning research with operational goals
Bridging the gap between academic exploration and production requirements requires deliberate planning. Researchers are increasingly collaborating with engineering teams to ensure novel architectures can be deployed at scale. This alignment prevents theoretical breakthroughs from remaining trapped in laboratory environments. Organizations are also establishing standardized testing protocols to validate new methods before integration. These practices ensure that innovation translates into tangible improvements. The synergy between research and operations accelerates the adoption of proven techniques. Sustainable growth depends on this continuous feedback loop.
What practical takeaways emerge from recent research trends?
The current landscape offers clear guidance for practitioners and organizations. Investing in data quality yields higher returns than scaling parameters indefinitely. Adopting modular architectures enables faster iteration and easier maintenance across diverse use cases. Implementing dynamic evaluation frameworks provides a more accurate measure of real-world readiness. These strategies collectively reduce risk while accelerating the path to deployment. Teams that prioritize efficiency and robustness will likely maintain a competitive advantage. The industry is moving toward sustainable, scalable development practices that prioritize long-term viability.
Aligning research with operational goals
Bridging the gap between academic exploration and production requirements requires deliberate planning. Researchers are increasingly collaborating with engineering teams to ensure novel architectures can be deployed at scale. This alignment prevents theoretical breakthroughs from remaining trapped in laboratory environments. Organizations are also establishing standardized testing protocols to validate new methods before integration. These practices ensure that innovation translates into tangible improvements. The synergy between research and operations accelerates the adoption of proven techniques. Sustainable growth depends on this continuous feedback loop.
Conclusion
The trajectory of machine learning research has settled into a phase of deliberate refinement. The initial excitement surrounding unprecedented scale has given way to a more grounded approach focused on sustainable development. Efficiency, robust evaluation, and architectural flexibility now guide the direction of innovation. This maturation ensures that foundational models become more reliable, accessible, and aligned with practical needs. The coming months will likely reveal further optimizations as the community continues to prioritize quality over quantity in every stage of development and testing.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.








Comments (0)