Understanding the Four Primary Approaches to Large Language Model Evaluation
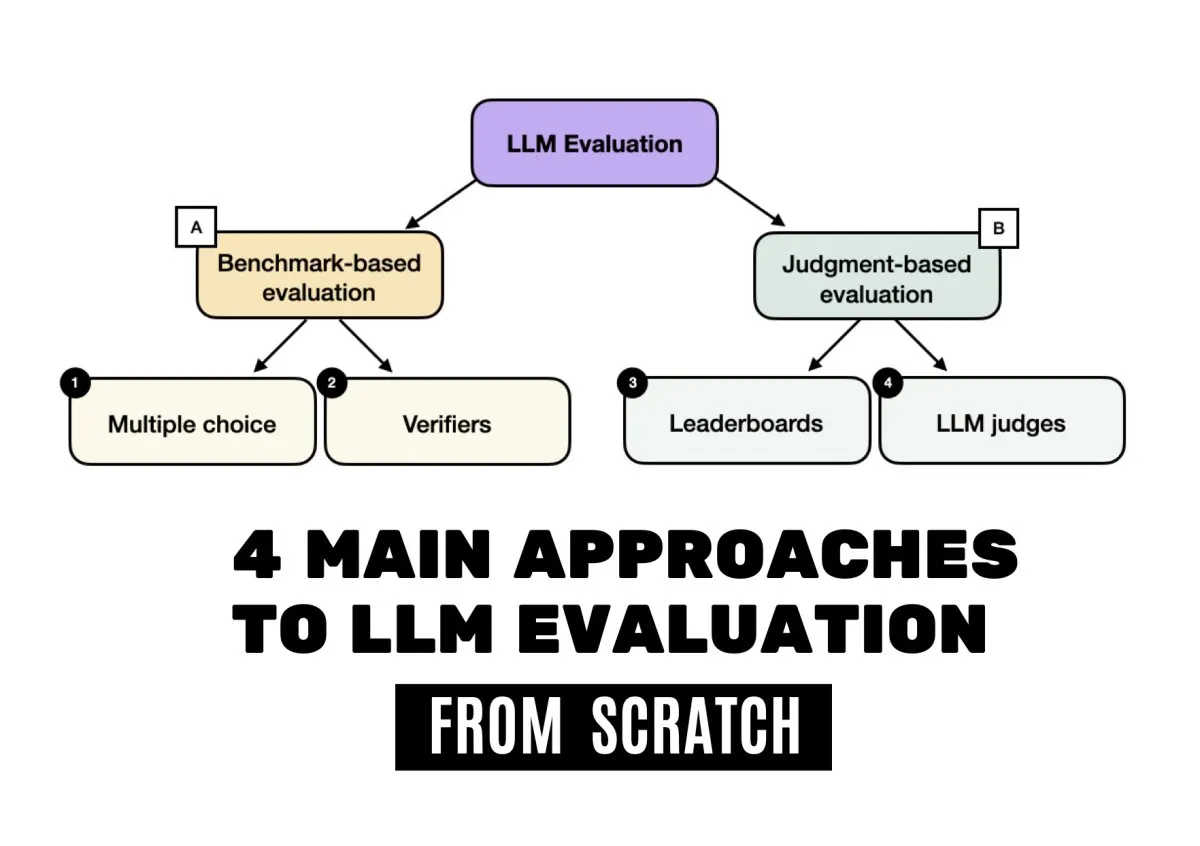
Evaluating large language models demands a multifaceted approach that combines standardized testing, automated verification, community benchmarking, and computational judging. Each methodology addresses distinct aspects of model capability, requiring practitioners to select frameworks aligned with specific deployment goals and technical constraints.
What Defines the Four Primary Approaches to Large Language Model Evaluation?
The assessment landscape has evolved significantly as generative systems have grown in complexity. Early evaluation relied heavily on simple accuracy counts, but modern requirements demand more nuanced measurement. The field currently centers on four distinct methodological pillars. Multiple-choice benchmarks provide standardized testing environments where models must select correct answers from predefined options. Automated verifiers apply deterministic rules to validate outputs against ground truth. Community leaderboards aggregate results across diverse tasks to establish comparative rankings. Computational judges utilize advanced systems to score open-ended responses using structured rubrics. Each approach serves a specific purpose within the broader evaluation ecosystem.
How Do Multiple-Choice Benchmarks Function in Practice?
Standardized testing frameworks operate by presenting models with structured queries and a fixed set of potential responses. The system generates the query, defines the options, and records which selection the model produces. Researchers then compare the output against the verified correct answer to calculate accuracy rates. This methodology offers several practical advantages for initial screening. The format ensures consistent input structure, which simplifies statistical analysis across different architectures. It also enables rapid iteration during development cycles, allowing teams to track incremental improvements efficiently. However, this approach carries inherent limitations that require careful consideration.
The primary constraint of this testing format involves prompt sensitivity and response formatting. Models trained on internet corpora may recognize specific benchmark questions, leading to inflated performance metrics that do not reflect genuine understanding. Furthermore, multiple-choice formats struggle to assess open-ended reasoning, creative synthesis, or nuanced contextual adaptation. The rigid structure forces models into binary decisions rather than evaluating the quality of their generated content. Developers must therefore supplement these benchmarks with alternative assessment methods to capture a complete picture of system capability.
Why Do Automated Verifiers and Deterministic Metrics Remain Essential?
Deterministic evaluation methods rely on explicit rules to compare model outputs against expected results. These verifiers measure exact string matches, token overlap, or structural compliance with predefined templates. The approach proves particularly valuable for technical domains where precision matters, such as code generation, mathematical computation, and data extraction. When a program must execute correctly or a calculation must yield an exact result, fuzzy matching becomes insufficient. Automated verifiers eliminate subjective interpretation by applying strict computational checks to every generated output.
The strength of this methodology lies in its reproducibility and computational efficiency. Teams can run these checks continuously during training or fine-tuning phases without incurring heavy costs. The immediate feedback loop allows engineers to identify systematic failures and adjust parameters accordingly. Nevertheless, deterministic metrics cannot assess linguistic fluency, logical coherence, or creative problem-solving. They measure compliance with explicit instructions rather than the underlying quality of the reasoning process. Practitioners must recognize that high verification scores do not automatically translate to reliable real-world performance.
Technical domains frequently require specialized evaluation pipelines that integrate these verifiers directly into continuous integration workflows. When models generate structured data or executable scripts, automated validation prevents downstream failures. Engineers can configure threshold parameters that trigger alerts when output quality drops below acceptable standards. This proactive monitoring reduces operational risk and maintains system reliability across complex deployment environments.
What Role Do Community Leaderboards Play in Shaping Development?
Public ranking systems aggregate evaluation results across numerous tasks, datasets, and methodologies to create comparative visibility. These platforms establish standardized protocols that allow different teams to measure progress against common baselines. The competitive environment drives rapid innovation by highlighting performance gaps and encouraging methodological improvements. Researchers analyze leaderboards to identify which architectural choices yield superior results across diverse linguistic and logical tasks. The transparency fosters accountability and accelerates the collective understanding of model capabilities.
The influence of these ranking platforms extends beyond academic research into practical deployment strategies. Organizations review aggregated performance data to select foundation models that align with specific industry requirements. The standardized comparisons reduce the friction involved in vendor evaluation and technical procurement. However, leaderboards also introduce challenges related to dataset contamination and overfitting to public benchmarks. Teams that optimize exclusively for ranking positions may neglect unmeasured dimensions of reliability, safety, and contextual adaptability. Sustainable development requires balancing competitive metrics with comprehensive internal validation processes. Many engineering teams now reference structured deployment frameworks, such as LaunchDarkly's approach to AI-powered product management, to align benchmark results with actual user experience and operational stability.
How Are Large Language Models Leveraged as Judges?
The emergence of computational judging represents a significant shift toward automated, scalable assessment frameworks. Instead of relying on human annotators or rigid rules, developers deploy advanced systems to evaluate open-ended outputs using structured criteria. These judges receive detailed prompts containing evaluation rubrics, scoring guidelines, and contextual examples. The system analyzes the generated response, compares it against the rubric, and assigns a numerical or categorical score. This methodology enables the assessment of complex dimensions such as tone, reasoning quality, factual consistency, and instruction following.
The primary advantage of this approach is its flexibility and capacity to handle nuanced tasks. Traditional metrics fail when outputs require contextual judgment or when multiple valid answers exist. Computational judges can weigh competing factors, recognize subtle improvements, and provide granular feedback. The process scales efficiently across large datasets, allowing continuous monitoring during iterative development cycles. Organizations can integrate these evaluation systems into their deployment pipelines to maintain quality standards. The methodology also supports the assessment of emergent capabilities that lack established ground truth references.
Implementing computational judges requires careful attention to prompt design and bias mitigation. The evaluating system inevitably inherits patterns from its training data, which can influence scoring consistency. Developers must construct neutral rubrics, test for positional bias, and validate scores against human baselines. The approach works best when combined with complementary evaluation methods rather than standing alone. Practitioners who understand these limitations can deploy computational judges effectively while maintaining rigorous quality control standards.
Continuous refinement of these judging frameworks involves periodic calibration against diverse human evaluation panels. Teams regularly audit scoring distributions to detect drift or systematic preference biases. Regular updates to rubric definitions ensure that the evaluating system adapts to evolving task requirements. This iterative calibration process maintains alignment between automated scoring and actual human judgment standards.
The Future of Model Assessment and Continuous Improvement
The evaluation landscape will continue evolving as generative systems tackle increasingly complex reasoning tasks. Development teams must adopt hybrid strategies that combine standardized testing, automated verification, community benchmarking, and computational scoring. No single methodology captures the full spectrum of system capability, making comprehensive assessment essential. Researchers will likely develop more sophisticated rubrics that account for contextual adaptation, safety alignment, and long-horizon reasoning. Practitioners should prioritize transparent evaluation protocols that reflect actual deployment conditions rather than artificial testing environments.
Organizations seeking to integrate advanced systems into their workflows should focus on practical validation over theoretical rankings. Understanding the strengths and limitations of each assessment approach enables more informed technical decisions. Teams that align their evaluation strategies with specific operational requirements will achieve more reliable outcomes. The continuous refinement of measurement frameworks will ultimately determine how effectively these systems serve complex industrial, scientific, and creative applications. Sustainable progress depends on rigorous, transparent, and context-aware assessment practices.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.










Comments (0)