Architectural Principles and Implementation Workflows for Open-Source LLMs
This article examines the architectural principles, implementation challenges, and ecosystem implications of building leading open-weight language models from the ground up, highlighting the technical workflows and broader industry shifts driving transparent artificial intelligence development.
The rapid evolution of large language models has fundamentally shifted how researchers and engineers approach artificial intelligence development. Rather than relying exclusively on proprietary systems, the community increasingly turns to open-weight architectures that allow for transparent inspection, modification, and deployment. This shift has prompted a rigorous examination of how these systems are constructed, optimized, and integrated into production environments.
What is the architectural foundation of modern open-weight language models?
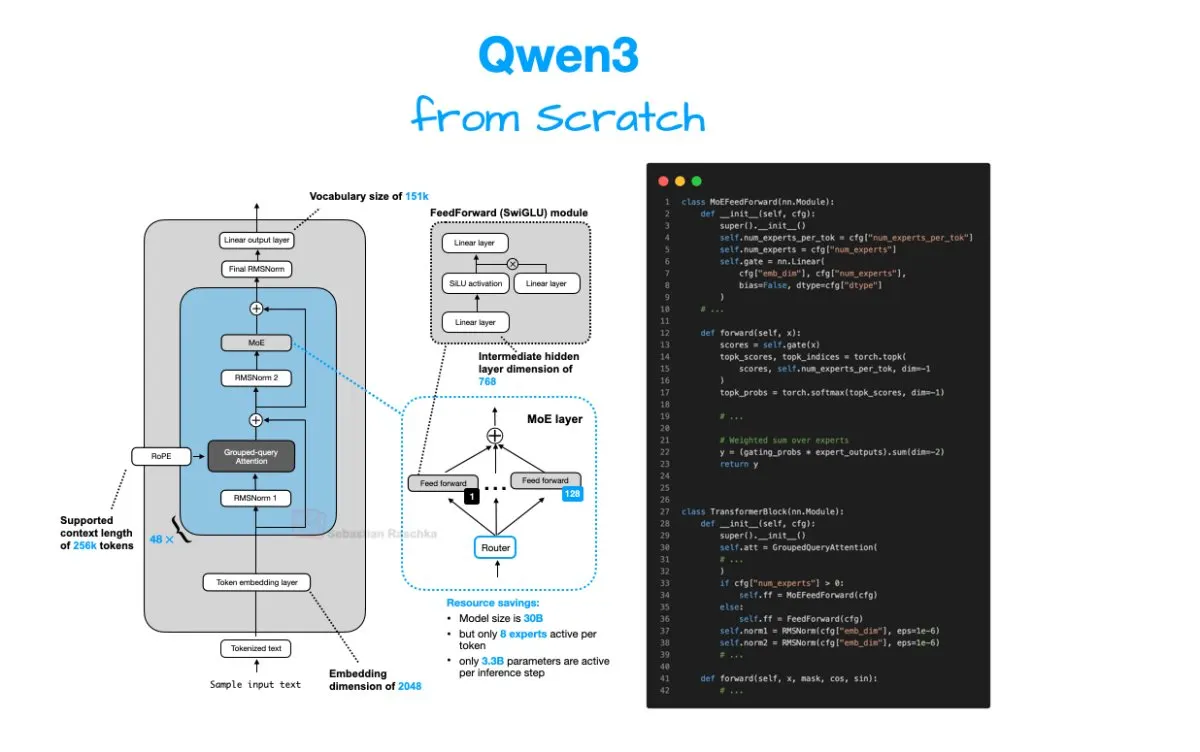
Modern large language models rely on transformer-based architectures that process sequential data through layered attention mechanisms. These architectures enable the model to weigh the importance of different input tokens relative to one another, creating a dynamic representation of context. Engineers designing these systems from scratch must carefully configure the dimensionality of hidden states, the number of attention heads, and the depth of the network. Each architectural decision directly influences computational requirements, memory footprint, and overall inference speed.
The transition from dense networks to mixture-of-experts configurations has further refined efficiency, allowing models to activate only a subset of parameters during processing. This selective activation reduces latency while maintaining substantial representational capacity. Understanding these foundational components is essential for anyone attempting to replicate or adapt such systems. The underlying mathematics of positional encoding, normalization layers, and feed-forward transformations remain consistent across most contemporary implementations, providing a standardized framework for development.
Researchers continuously experiment with activation functions, dropout rates, and weight initialization strategies to stabilize training dynamics. These choices collectively define the model’s ability to generalize across diverse linguistic structures and reasoning tasks. The interplay between architectural depth and width determines how effectively a model captures long-range dependencies versus fine-grained local patterns. Engineers must balance theoretical capacity against practical hardware limitations to achieve functional deployment.
Decoding attention and parameter scaling
Attention mechanisms form the core of sequential processing, calculating pairwise relationships across input sequences. As models scale, the quadratic complexity of self-attention drives engineers to explore approximations and sparse attention patterns. Parameter scaling follows a different trajectory, where increasing model size requires proportional adjustments to batch size, learning rate, and computational resources. Engineers must balance theoretical capacity against practical hardware limitations.
The interplay between architectural depth and width determines how effectively a model captures long-range dependencies versus fine-grained local patterns. Researchers continuously experiment with activation functions, dropout rates, and weight initialization strategies to stabilize training dynamics. These choices collectively define the model’s ability to generalize across diverse linguistic structures and reasoning tasks. The mathematical foundations remain stable even as hardware capabilities expand.
Why does open-source licensing matter for the broader AI ecosystem?
The release of open-weight models has created a parallel development track outside traditional corporate boundaries. Licensing frameworks dictate how researchers can modify, redistribute, and commercially deploy these architectures. Open licenses typically permit academic exploration and internal commercial use while restricting certain redistribution rights. This structure encourages widespread experimentation without granting unrestricted control over derivative works. Organizations benefit from reduced dependency on external providers, enabling custom fine-tuning for specialized domains.
The transparency of open-weight releases also facilitates independent auditing of safety mechanisms, bias mitigation strategies, and training data provenance. When development occurs in public repositories, peer review becomes a continuous process rather than a retrospective evaluation. This collaborative environment accelerates innovation cycles and establishes shared standards for model evaluation and benchmarking. The ecosystem thrives on accessible documentation and reproducible experimental setups.
Legal frameworks surrounding artificial intelligence development continue to evolve alongside technical capabilities. Contributors to open-weight projects must carefully delineate permitted use cases, commercial restrictions, and modification rights. Ethical considerations extend beyond licensing terms to encompass data sourcing, computational resource allocation, and environmental impact. Organizations deploying these models assume responsibility for monitoring output quality and preventing misuse.
Navigating legal and ethical boundaries
Legal frameworks surrounding artificial intelligence development continue to evolve alongside technical capabilities. Contributors to open-weight projects must carefully delineate permitted use cases, commercial restrictions, and modification rights. Ethical considerations extend beyond licensing terms to encompass data sourcing, computational resource allocation, and environmental impact. Organizations deploying these models assume responsibility for monitoring output quality and preventing misuse.
The tension between open collaboration and controlled distribution shapes how rapidly new architectures propagate through the industry. Clear documentation and standardized compliance tools help developers navigate these complexities without stifling creative exploration. When institutions align their development practices with established licensing standards, they reduce legal friction and accelerate internal adoption. This alignment supports sustainable growth across research and commercial divisions.
How do engineers approach training and inference pipelines from scratch?
Constructing a complete training pipeline requires coordinating data ingestion, preprocessing, optimization routines, and checkpoint management. Engineers begin by curating high-quality text corpora, applying deduplication strategies, and tokenizing sequences into standardized integer representations. The optimization phase demands careful selection of learning rate schedules, gradient accumulation techniques, and mixed-precision arithmetic to stabilize convergence. Distributed training across multiple accelerators introduces synchronization challenges that require robust communication protocols.
Inference pipelines differ significantly, prioritizing latency reduction, memory optimization, and dynamic batching. Quantization methods compress model weights without substantial accuracy degradation, enabling deployment on constrained hardware. Engineers must also implement caching mechanisms, speculative decoding, and adaptive token generation to maximize throughput. The entire workflow depends on reliable monitoring tools that track loss trajectories, gradient norms, and hardware utilization metrics. Accelerating engineering cycles often requires adopting modular infrastructure that scales with demand.
Distributed training across multiple accelerators introduces synchronization challenges that require robust communication protocols and load balancing strategies. Network overhead becomes a critical factor when scaling beyond a single node, requiring optimized all-reduce operations and gradient compression techniques. Storage infrastructure must handle massive checkpoint files without introducing bottlenecks during recovery or evaluation phases. Software frameworks provide abstractions that simplify distributed coordination, but low-level tuning remains necessary for peak performance.
Overcoming computational and infrastructure bottlenecks
Hardware constraints frequently dictate the feasibility of large-scale model development. Memory bandwidth, interconnect speeds, and storage throughput all influence training efficiency. Engineers often employ pipeline parallelism and tensor parallelism to distribute workloads across available accelerators. Network overhead becomes a critical factor when scaling beyond a single node, requiring optimized all-reduce operations and gradient compression techniques.
Storage infrastructure must handle massive checkpoint files without introducing bottlenecks during recovery or evaluation phases. Software frameworks provide abstractions that simplify distributed coordination, but low-level tuning remains necessary for peak performance. Continuous integration and automated testing ensure that incremental updates do not destabilize established training trajectories. Reliable infrastructure reduces downtime and improves reproducibility across experimental runs.
What are the practical implications for research and commercial deployment?
The availability of adaptable architectures has transformed how institutions approach artificial intelligence research. Academic groups can now replicate published results, verify claims, and build upon existing foundations without prohibitive costs. Commercial entities leverage these models as starting points for domain-specific fine-tuning, reducing time-to-market for specialized applications. The modular nature of modern architectures allows engineers to swap components, test alternative configurations, and experiment with novel training objectives.
This flexibility accelerates hypothesis validation and reduces reliance on trial-and-error approaches. Organizations that invest in understanding implementation details gain strategic advantages in customizing performance, optimizing resource allocation, and maintaining compliance with internal governance standards. The open ecosystem fosters continuous improvement through shared knowledge, peer review, and collaborative problem-solving. Institutions that prioritize architectural literacy remain positioned to adapt to emerging technical requirements.
Translating laboratory experiments into reliable production environments requires careful alignment of development practices. Research prototypes often prioritize flexibility over stability, while production systems demand rigorous testing, version control, and rollback capabilities. Engineers must standardize data formats, enforce strict input validation, and implement automated regression testing. Monitoring dashboards track performance drift, resource consumption, and error rates to maintain service reliability.
Bridging theoretical research and production systems
Translating laboratory experiments into reliable production environments requires careful alignment of development practices. Research prototypes often prioritize flexibility over stability, while production systems demand rigorous testing, version control, and rollback capabilities. Engineers must standardize data formats, enforce strict input validation, and implement automated regression testing. Monitoring dashboards track performance drift, resource consumption, and error rates to maintain service reliability.
Collaboration between research teams and operations staff ensures that architectural innovations translate smoothly into scalable deployments. Documentation becomes a critical asset, capturing design decisions, failure modes, and optimization strategies for future reference. When engineering workflows emphasize reproducibility, organizations reduce technical debt and accelerate future development cycles. The boundary between research and production continues to blur as tools mature.
Conclusion
The development of transparent artificial intelligence systems continues to reshape technical workflows and industry standards. Engineers who master implementation details gain the ability to adapt architectures rapidly, optimize resource utilization, and maintain independent control over deployment pathways. The open ecosystem fosters continuous improvement through shared knowledge, peer review, and collaborative problem-solving. Organizations that prioritize architectural literacy and systematic development practices will remain positioned to navigate evolving technical landscapes effectively.
As computational capabilities expand and licensing frameworks mature, the industry will witness further convergence between academic research and commercial application. Sustainable development depends on rigorous engineering practices, transparent documentation, and responsible deployment strategies. The trajectory of modern language model development points toward increasingly accessible, modular, and auditable systems that empower broader innovation across technical disciplines.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.








Comments (0)