From GPT-2 to gpt-oss: Analyzing Architectural Advances
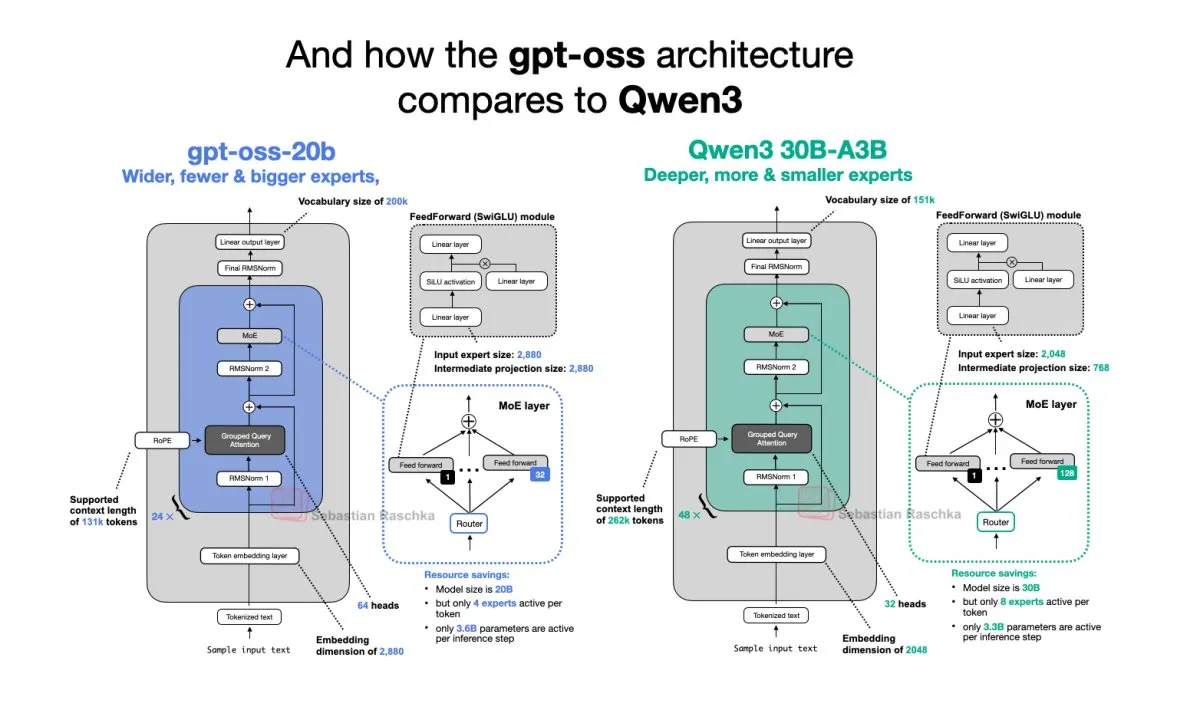
The evolution from early proprietary transformer models to modern open-weight architectures reflects a fundamental shift in how artificial intelligence systems are designed, scaled, and distributed. By examining structural modifications, attention mechanisms, and parameter efficiency, researchers can identify the engineering choices that enabled broader accessibility without compromising computational performance or research transparency.
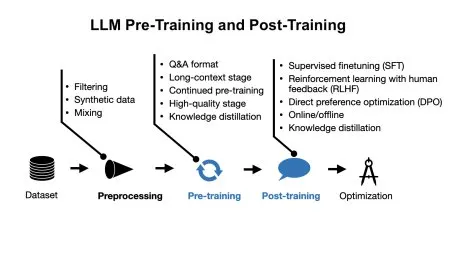
The trajectory of large language models has consistently demonstrated a shift from closed, proprietary systems toward transparent, open-weight architectures. Early iterations laid the groundwork for modern generative artificial intelligence, but the underlying engineering principles have evolved significantly over time. Understanding these architectural advances requires examining how foundational designs adapted to computational constraints, scaling laws, and the growing demand for accessible research tools. This analysis explores the structural progression from initial OpenAI GPT-2 deployments to contemporary open-source frameworks, highlighting the technical milestones that enabled broader academic and industrial adoption.
What is the architectural foundation of the early GPT series?
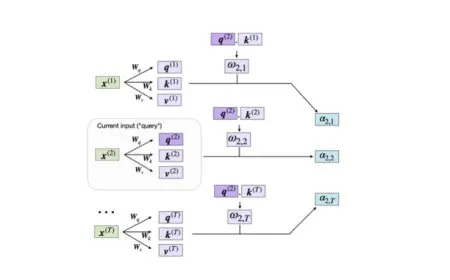
The initial generation of generative transformer models established a standardized blueprint for sequential text processing. These early systems relied on a decoder-only structure, which prioritized autoregressive prediction across token sequences. The core mechanism utilized scaled dot-product attention, allowing the model to weigh the relevance of preceding tokens dynamically during training. Unlike earlier encoder-decoder frameworks that required bidirectional context, the decoder-only approach optimized inference speed and reduced computational overhead. This architectural choice proved critical for scaling model capacity, as it enabled parallel processing during training while maintaining causal constraints during generation.
The foundational design also incorporated positional encoding schemes to preserve sequence order, a necessary adjustment since the attention mechanism itself lacks inherent temporal awareness. Researchers later refined these positional representations to improve long-context retention and gradient stability. The initial iterations demonstrated that massive parameter counts could capture linguistic patterns, but they also exposed limitations in memory utilization and training efficiency. Subsequent iterations addressed these constraints by introducing optimized normalization techniques and refined activation functions. The architectural decisions made during this period established the baseline for all future generative systems, proving that structural simplicity could scale effectively when paired with sufficient computational resources.
How did open-weight models shift the development paradigm?
The transition from closed research initiatives to publicly accessible model weights fundamentally altered how artificial intelligence is developed and evaluated. Open-weight frameworks allowed independent researchers to inspect internal representations, audit for bias, and modify architectural components without relying on proprietary application programming interfaces. This transparency accelerated the development of specialized fine-tuning techniques and domain-specific adaptations. Academic institutions and independent developers could now replicate training runs, verify claimed performance metrics, and propose structural improvements based on empirical evidence. The open ecosystem also fostered competition in efficiency optimization, prompting engineers to explore quantization methods, sparse activation patterns, and memory-aware training loops.
Rather than treating model capacity as a proprietary secret, the community began sharing architectural blueprints that prioritized reproducible engineering over commercial exclusivity. This shift encouraged the standardization of evaluation benchmarks and promoted collaborative debugging of failure modes. Researchers could experiment with alternative attention variants, positional encoding strategies, and optimization schedules without legal restrictions. The resulting proliferation of architectural variants demonstrated that iterative community feedback could accelerate progress more rapidly than isolated development cycles. The open-weight model has since become a standard reference point for evaluating new structural innovations in generative systems, echoing the collaborative spirit seen in initiatives like the 1,000 Scientist AI Jam Session.
Why does efficiency matter in modern transformer designs?
Computational efficiency has emerged as a critical constraint as model capacity continues to expand. Training and deploying large-scale architectures requires substantial memory bandwidth, parallel processing capabilities, and optimized data movement protocols. Early transformer implementations struggled with quadratic scaling in attention computation, which limited context window size and increased training costs. Engineers responded by introducing attention mechanisms that reduce computational complexity while preserving contextual fidelity. These optimizations include sparse attention patterns, local window constraints, and recurrent state approximations that lower memory footprint during inference. Efficiency improvements also extend to training stability, where gradient checkpointing, mixed-precision arithmetic, and dynamic batch sizing allow larger models to train on limited hardware configurations.
The push for efficiency has driven architectural decisions that prioritize linear scaling over quadratic scaling, enabling longer context retention without proportional increases in computational demand. Researchers have also explored alternative normalization schemes and activation functions that reduce memory allocation during backward passes. These structural adjustments allow models to maintain performance while operating within realistic deployment constraints. The emphasis on efficiency has shifted the focus from raw parameter count to architectural elegance, where every component must justify its computational cost. This pragmatic approach ensures that future iterations remain accessible to institutions with varying hardware capabilities.
How do recent architectures compare across different research tracks?
Contemporary open-source frameworks demonstrate divergent engineering philosophies while converging on similar performance objectives. Some research tracks prioritize parameter efficiency through mixture-of-experts architectures, routing tokens through specialized expert networks to reduce active computation per inference step. Other approaches focus on refining attention mechanisms, introducing hybrid combinations that balance global context capture with localized pattern recognition. The comparison across these tracks reveals a common trajectory toward modularity and scalability. Engineers consistently evaluate trade-offs between context length, inference latency, and training stability. While some frameworks emphasize dense parameter utilization, others explore sparse activation patterns that activate only a subset of weights per sequence.
These architectural divergences reflect differing priorities in deployment environments, from resource-constrained edge devices to centralized high-performance clusters. Researchers also examine how optimization schedules and data curation strategies interact with structural choices. The resulting landscape shows that no single architecture dominates universally, but rather that contextual requirements dictate optimal design selections. This diversity encourages continuous benchmarking and structural refinement across the research community. Understanding these structural differences helps practitioners select appropriate frameworks for specific operational requirements. The community continues to document these comparisons, ensuring that architectural knowledge remains accessible and rigorously evaluated.
What are the practical implications for developers and researchers?
The architectural evolution of open-weight models directly influences how practitioners deploy and adapt generative systems in real-world applications. Developers must now evaluate structural compatibility when integrating models into existing software pipelines, considering factors such as memory requirements, inference latency, and fine-tuning flexibility. Researchers benefit from standardized architectural baselines that simplify ablation studies and comparative analysis. The availability of open structural blueprints reduces duplication of engineering efforts and accelerates iterative experimentation. Practitioners can now apply architectural modifications directly to baseline frameworks, testing structural hypotheses without rebuilding foundational components from scratch. This accessibility lowers the barrier to entry for specialized research, enabling smaller teams to contribute meaningful structural innovations.
The focus on efficiency and modularity also encourages cross-disciplinary collaboration, as engineers from hardware, optimization, and applied domains can align on shared architectural standards. As structural complexity increases, documentation and reproducibility become essential for sustained progress. The community continues to refine these standards, ensuring that architectural transparency remains a core principle of generative system development. Practitioners who understand these foundational shifts can navigate implementation challenges more effectively. The ongoing refinement of these structural principles will continue to shape how artificial intelligence systems are engineered and deployed in the coming years.
Conclusion
The progression from early decoder-only frameworks to contemporary open-weight architectures reflects a sustained engineering effort to balance capacity, efficiency, and accessibility. Structural innovations have consistently addressed computational constraints while expanding contextual capabilities. The shift toward transparent model development has accelerated iterative refinement and democratized access to generative technology. Future architectural directions will likely emphasize modular design, adaptive computation, and standardized evaluation protocols. The continuous evaluation of architectural trade-offs ensures that future developments remain grounded in empirical evidence rather than speculative engineering. Researchers and engineers alike benefit from this transparent approach, which prioritizes verifiable progress over proprietary secrecy. As computational resources and algorithmic techniques continue to mature, the structural foundations established during this era will guide the next generation of generative systems. The commitment to architectural openness will remain a defining characteristic of sustainable artificial intelligence research.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.






Comments (0)