Modern LLM Architecture Comparison: Dense, Sparse, and Hybrid Design
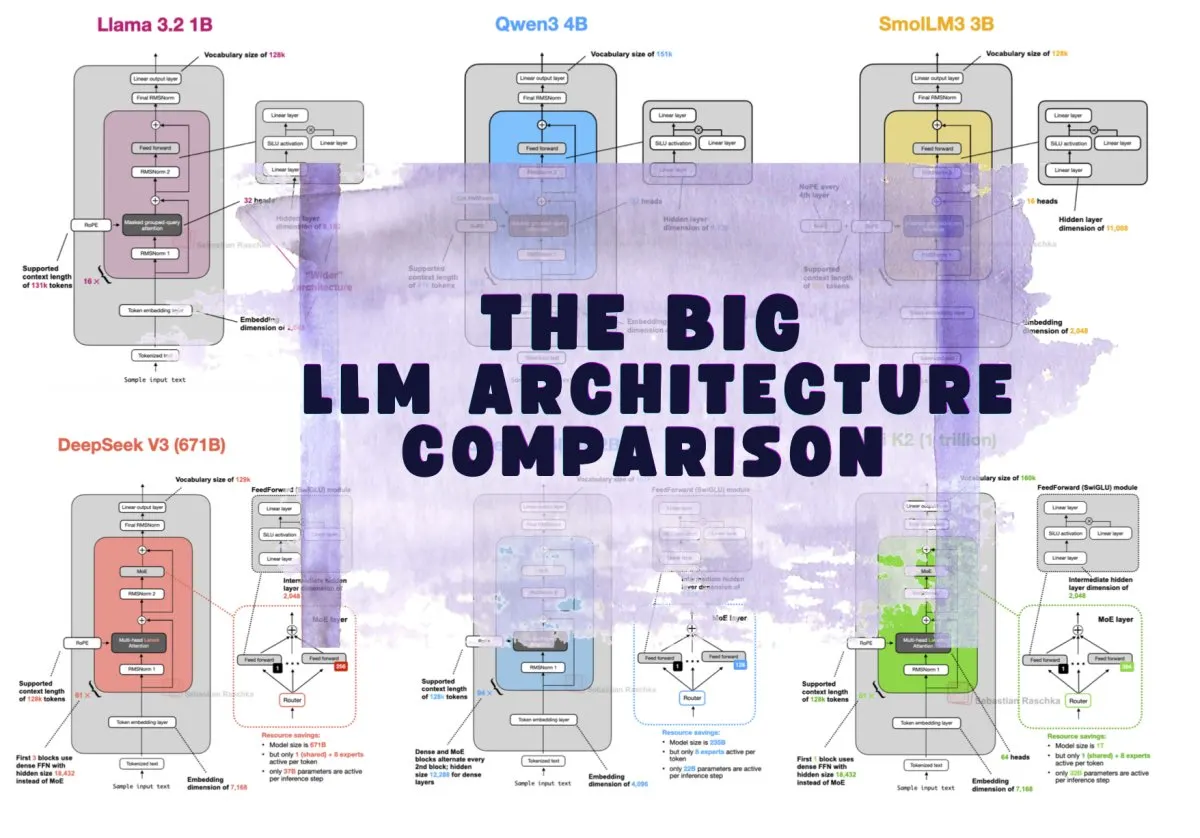
Modern large language models are moving beyond uniform dense networks toward specialized architectural frameworks that optimize computational efficiency. This analysis explores the trade-offs between sparse and dense designs, examines hardware utilization patterns, and outlines how hybrid approaches may shape the next generation of scalable artificial intelligence systems.
The rapid evolution of large language models has fundamentally altered how researchers approach computational efficiency and architectural design. As systems grow in scale, the underlying structures that govern information processing must adapt to new hardware realities and deployment constraints. Understanding these structural paradigms is essential for evaluating how future models will balance performance with resource utilization.
What is the fundamental shift in modern large language model design?
The transition from monolithic networks to modular architectures represents a decisive change in how artificial intelligence systems process information. Early implementations relied on uniform computational layers where every parameter participated in every inference step. This approach guaranteed consistent gradient flow but demanded substantial memory bandwidth and processing power. As model capacity expanded, researchers recognized that uniform participation created unnecessary computational overhead. The industry gradually shifted toward selective activation paradigms that route specific tokens through specialized pathways. This structural evolution prioritizes targeted computation over blanket processing, fundamentally altering how training and inference workflows operate across distributed hardware clusters.
How do sparse and dense architectures differ in practice?
Dense networks maintain continuous parameter activation across all computational steps, ensuring that every input token interacts with the full model capacity. This uniformity simplifies training dynamics and stabilizes gradient propagation through deep layers. Sparse architectures, conversely, activate only a fraction of their total parameters for each processing step. This selective activation reduces computational load but introduces complex routing mechanisms that must distribute workloads evenly across available experts. Recent implementations, including DeepSeek-V3 and Kimi K2, demonstrate how routing efficiency directly impacts deployment viability. The practical divergence between these approaches becomes most apparent during deployment, where memory bandwidth and processor utilization dictate actual performance rather than theoretical parameter counts.
The mechanics of mixture of experts
Mixture of experts frameworks partition model capacity into distinct computational units that activate conditionally based on input characteristics. A gating network evaluates each incoming token and directs it to the most appropriate subset of parameters. This conditional routing enables massive scale while maintaining manageable computational requirements per inference step. However, the gating mechanism itself requires careful calibration to prevent load imbalance. When routing decisions cluster excessively on specific experts, training stability degrades and inference latency increases. Effective implementation demands continuous monitoring of expert utilization patterns and dynamic adjustment of routing thresholds.
Inference costs and hardware utilization
Computational efficiency during inference depends heavily on how well architectural choices align with available hardware capabilities. Dense models benefit from highly optimized matrix multiplication routines that maximize parallel processing throughput. Sparse configurations require additional routing logic that can introduce latency if not carefully implemented. Hardware manufacturers have responded by designing specialized accelerators that handle conditional computation more efficiently. The alignment between software architecture and physical silicon determines whether theoretical parameter counts translate into practical performance gains. Engineers must evaluate memory bandwidth, cache hierarchy, and interconnect speeds when selecting deployment configurations.
Why does architectural choice dictate deployment scalability?
The path from research prototype to production system hinges on how efficiently a model utilizes available infrastructure. Scaling laws traditionally suggested that larger parameter counts directly improved capability, but this relationship holds only when computational resources scale proportionally. Architectural decisions now determine whether added capacity yields diminishing returns or sustained improvements. Models that distribute computation intelligently can achieve comparable performance with significantly lower operational costs. This reality forces organizations to evaluate total cost of ownership, including energy consumption, hardware procurement, and maintenance overhead, rather than focusing exclusively on benchmark accuracy.
Memory bandwidth and compute efficiency
Memory bandwidth frequently becomes the primary bottleneck in large model deployment, regardless of raw processing power. Dense architectures require loading the entire parameter set into high-speed memory for every inference step, creating substantial data transfer overhead. Sparse designs mitigate this constraint by loading only active parameters, reducing memory pressure and improving throughput. However, the reduction in memory transfer must be balanced against the computational cost of routing decisions. Effective deployment strategies align model sparsity patterns with hardware memory hierarchies, ensuring that frequently accessed parameters remain readily available while less active components reside in slower storage tiers.
Routing mechanisms and load balancing
Dynamic routing determines which computational paths process each input token, making it a critical component of sparse system performance. Poorly calibrated routing leads to expert collapse, where a small subset of parameters handles most of the workload while others remain underutilized. Load balancing algorithms continuously monitor expert activation frequencies and adjust gating weights to distribute work evenly. Some implementations incorporate auxiliary loss functions that penalize imbalance during training, forcing the routing network to explore a wider range of computational pathways. Careful calibration of these mechanisms ensures stable training dynamics and consistent inference behavior across diverse input distributions.
What role does hybrid design play in next-generation systems?
The convergence of different computational paradigms points toward hybrid architectures that combine the strengths of multiple structural approaches. Researchers are exploring combinations of recurrent processing with attention mechanisms to capture long-range dependencies more efficiently. Hybrid models aim to retain the sequential processing advantages of earlier architectures while leveraging the parallel computation benefits of modern attention-based systems. This synthesis requires careful integration of distinct computational units, ensuring that data flows smoothly between different processing stages. The resulting frameworks seek to optimize both training stability and inference speed, offering a balanced path forward for scaling artificial intelligence systems.
Combining recurrent and attention paradigms
Integrating recurrent and attention mechanisms demands careful structural design to prevent computational redundancy. Recurrent layers excel at processing sequential information with constant memory overhead, while attention layers capture complex cross-token relationships at the cost of quadratic scaling. Hybrid implementations typically assign recurrent processing to early stages for sequence normalization and attention processing to later stages for contextual refinement. This division of labor reduces overall computational requirements while preserving the ability to model long-range dependencies. Engineers must carefully tune the transition boundaries between processing stages to maintain gradient flow and prevent information degradation across architectural boundaries.
Training stability and data efficiency
Complex hybrid architectures introduce additional training challenges that require careful management of gradient propagation and parameter updates. Different computational pathways may exhibit distinct convergence rates, making it difficult to synchronize optimization steps across the entire network. Regularization techniques must be adapted to prevent specific components from dominating the learning process. Data curation also becomes more critical, as hybrid models often require specialized preprocessing pipelines to align input formats with distinct architectural requirements. Successful training demands comprehensive monitoring of loss trajectories across all computational modules, ensuring that no single pathway becomes a bottleneck for overall system improvement.
How do data processing pipelines adapt to new architectural constraints?
Data preparation workflows must evolve alongside architectural innovations to maintain alignment between input formats and model expectations. Sparse systems require specialized tokenization strategies that minimize routing conflicts and prevent expert saturation during early training phases. Preprocessing pipelines now incorporate dynamic masking techniques that simulate sparsity patterns before actual deployment. This proactive approach helps identify potential bottlenecks in data distribution and allows engineers to adjust vocabulary boundaries accordingly. The integration of adaptive tokenization ensures that input sequences remain compatible with evolving parameter partitioning schemes.
Validation procedures also demand modification to accurately assess model behavior across diverse computational pathways. Traditional evaluation metrics often overlook routing efficiency and expert utilization patterns, leading to incomplete performance assessments. New validation frameworks incorporate hardware-aware benchmarks that measure actual inference latency, memory bandwidth consumption, and routing overhead. These metrics provide a more accurate representation of real-world deployment capabilities. Researchers must align validation protocols with target infrastructure specifications to ensure that architectural advantages translate into measurable operational improvements.
What implications do these structural changes hold for future research methodologies?
The shift toward modular computation is reshaping how scientific teams approach model development and experimentation. Researchers now evaluate architectural components as independent variables that can be swapped, tested, and optimized separately. This modularization accelerates iteration cycles by allowing targeted improvements without retraining entire networks. Cross-disciplinary collaboration has also increased, as hardware engineers and algorithm developers must work closely to align computational units with physical accelerator capabilities. The boundary between software design and hardware specification continues to blur, necessitating unified development frameworks.
Funding priorities and resource allocation are similarly affected by these structural transformations. Institutions are directing investment toward infrastructure that supports conditional computation and dynamic routing rather than static parameter scaling. Open-source initiatives are focusing on standardized routing protocols and interoperable expert libraries that enable broader experimentation. This collaborative environment mirrors efforts focused on accelerating engineering cycles across distributed research teams. The industry is gradually moving away from isolated development toward shared computational foundations that benefit the entire research community.
The trajectory of artificial intelligence development now depends less on raw parameter expansion and more on intelligent structural design. Organizations that prioritize architectural efficiency over brute-force scaling will likely achieve more sustainable progress. The industry continues to refine routing mechanisms, memory management strategies, and hybrid integration techniques to balance capability with practical constraints. Future advancements will emerge from systematic exploration of computational trade-offs rather than unchecked parameter growth. Engineers and researchers must remain focused on optimizing the intersection of algorithmic design and hardware reality. The next phase of progress will be defined by precision, not volume.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Wow
0
Wow
0
 Sad
0
Sad
0
 Angry
0
Angry
0
Christopher Holloway is the founder and director of Progressive Robot, a UK-based technology company. A full-stack engineer with more than two decades of experience, he works across PHP development, ecommerce, Linux infrastructure, technical SEO and AI automation, and writes here on technology, AI, hardware and software.









Comments (0)